Chapter 4 Describing, Exploring, and Comparing Data
Learning Outcome:
Calculate measures of central tendency, position, and spread, including standard deviation. Interpret quantitative data using graphs and descriptive statistics with emphasis on histograms and boxplots.
In this chapter, we will numerically describe distributions of quantitative variables. Distributions, such as histograms, can be described by three characteristics: shape, center, and spread.
4.1 Measures of Shape
Modes
The mode of some data is an observation with the greatest frequency. There can be more than one mode, but if all the observations have frequency 1, then there is no mode.
Mode is represented by a prominent peak in the distribution.
Unimodel Distribution
Bimodal Distribution
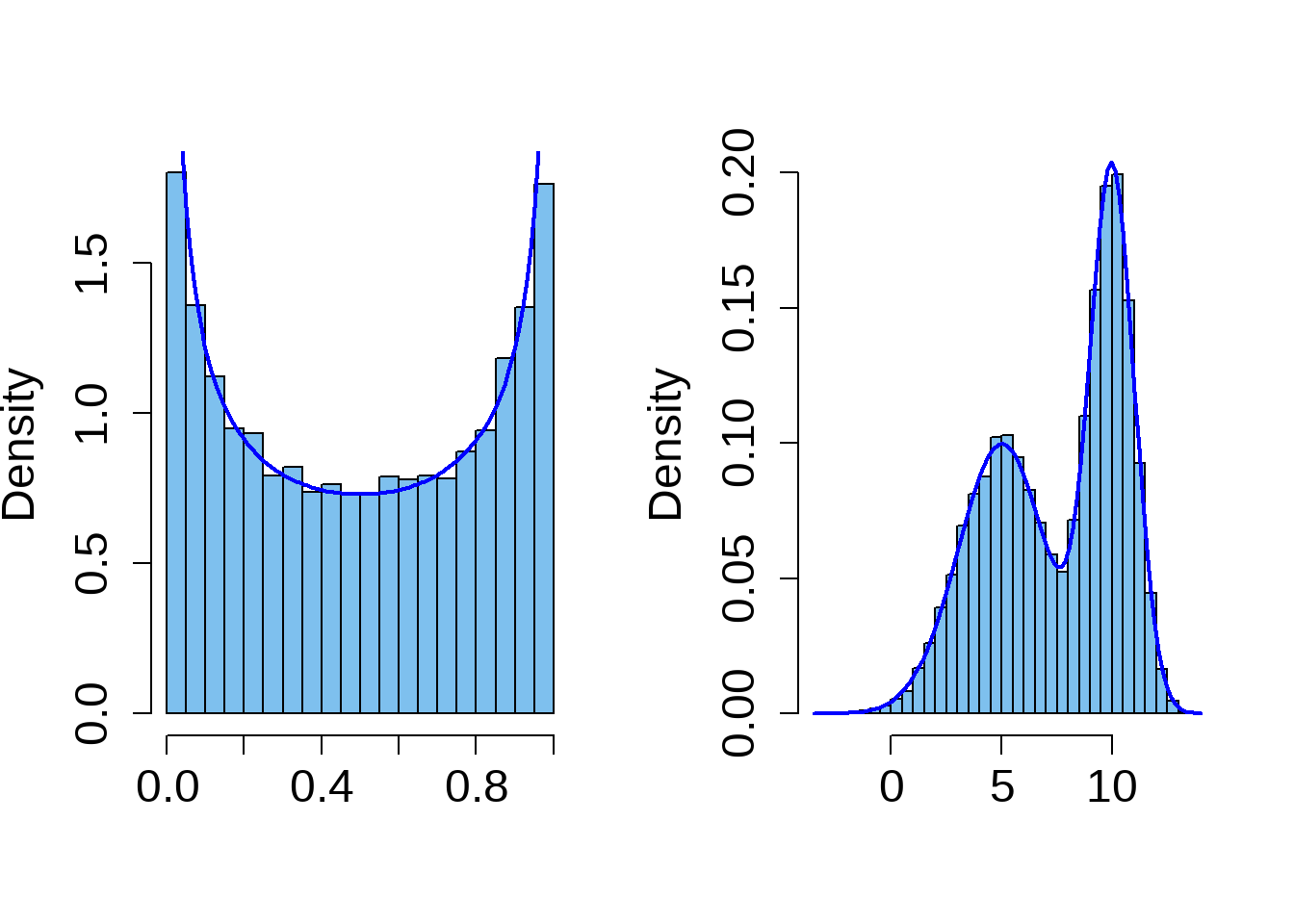
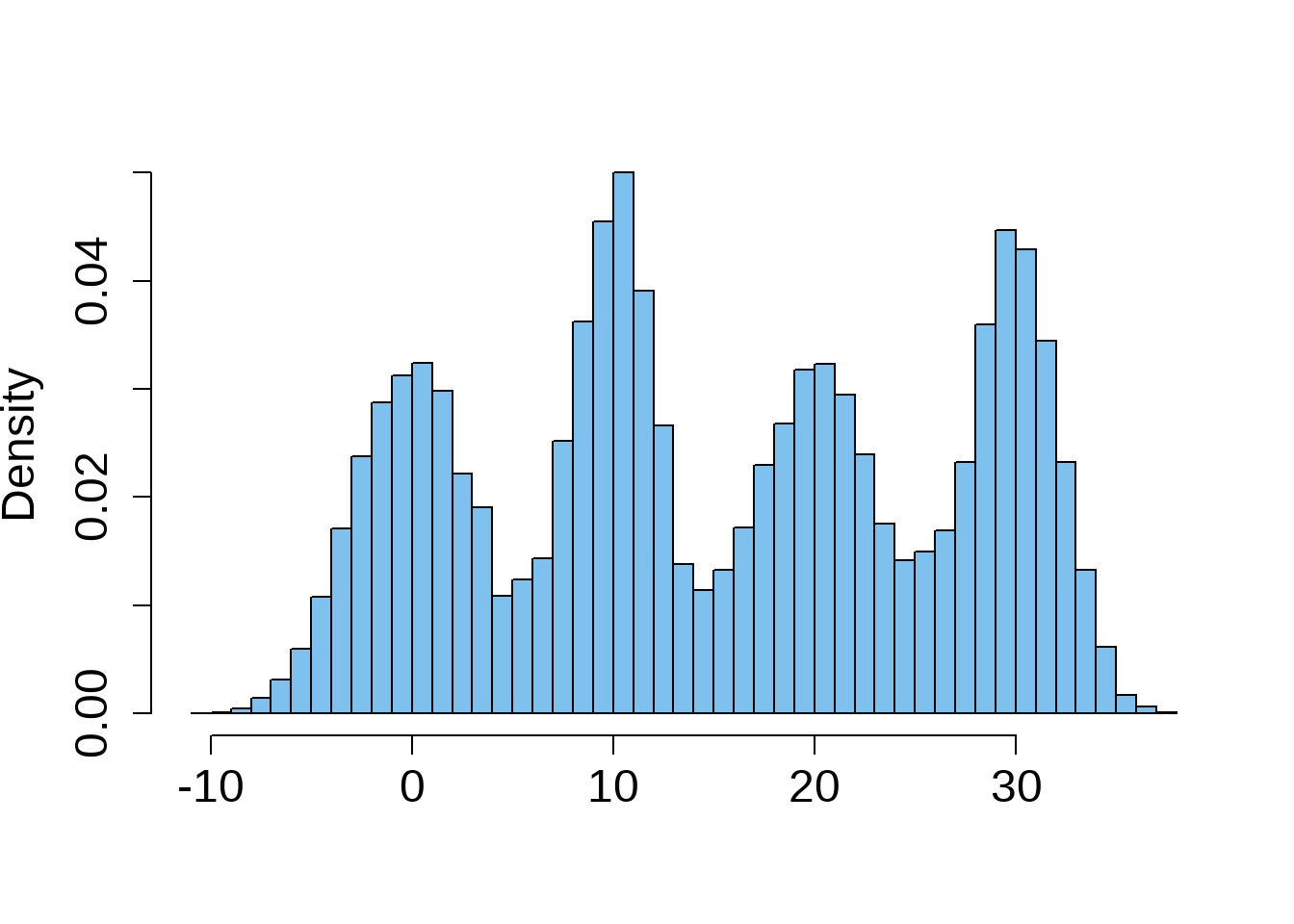
Multimodal Distribution
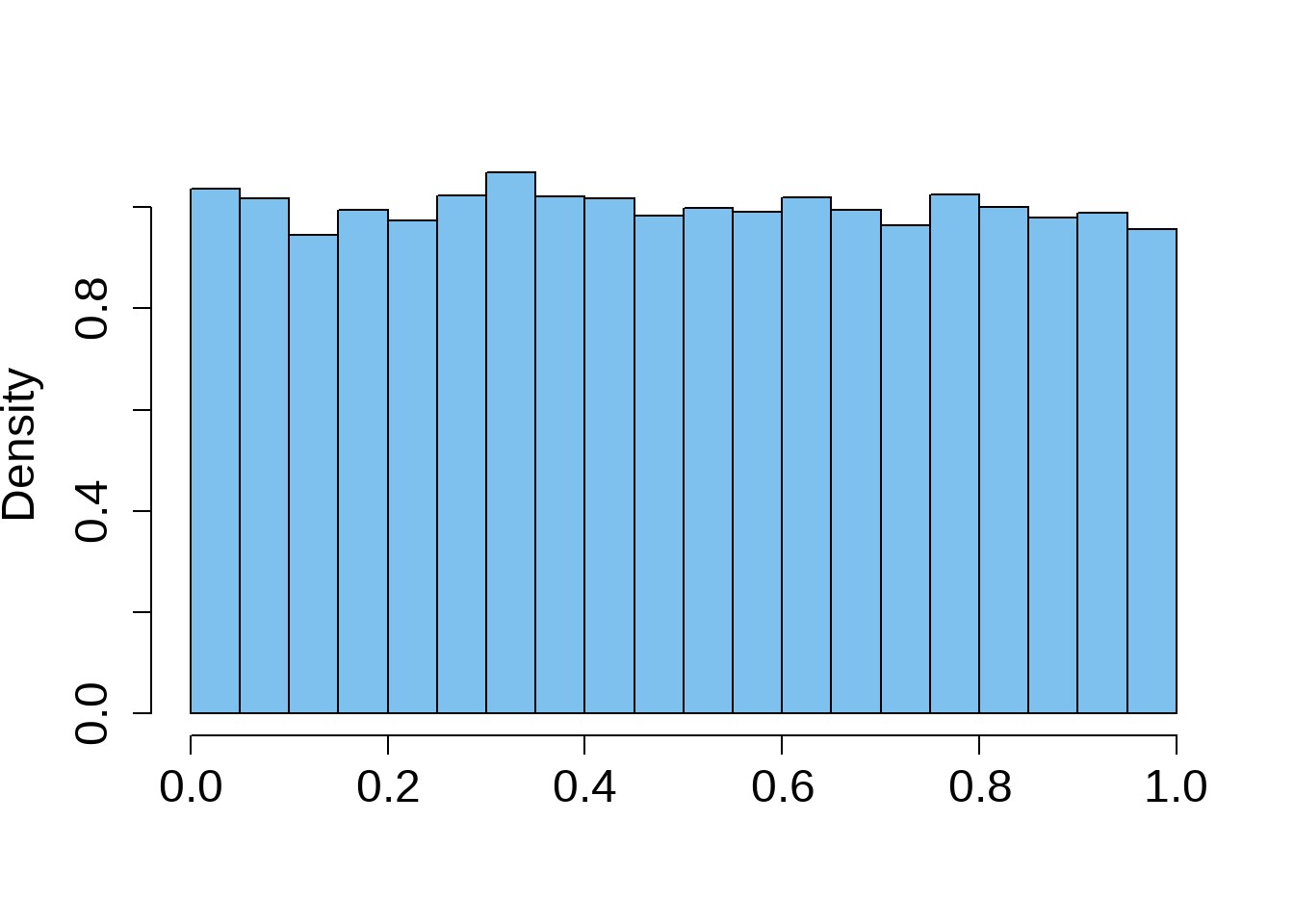
Uniform Distribution
All the bins have the same frequency, or at least close to the same frequency. It is a distribution without a mode.
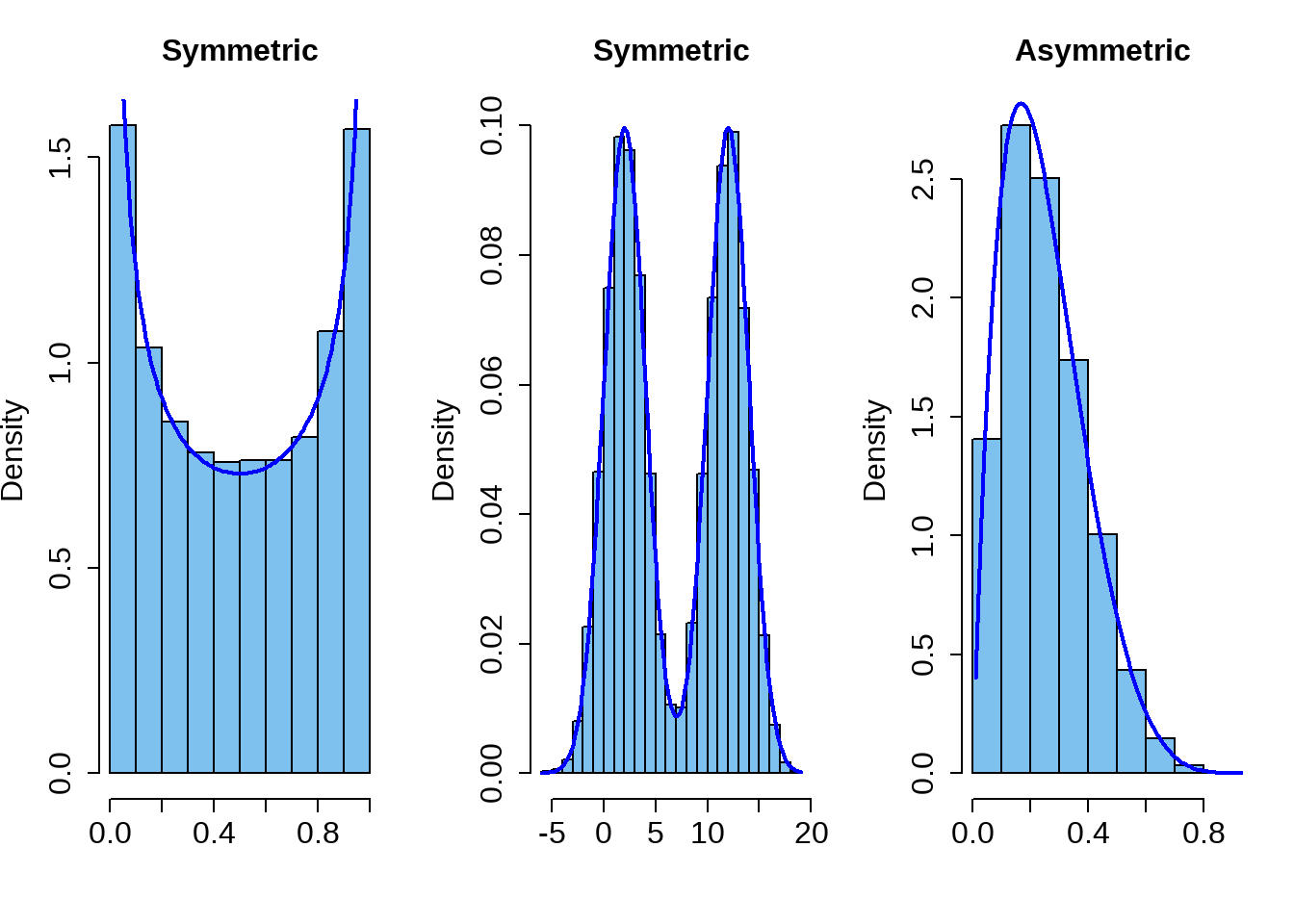
Symmetry
The histogram for a symmetric distribution will look the same on the left and the right of its center.
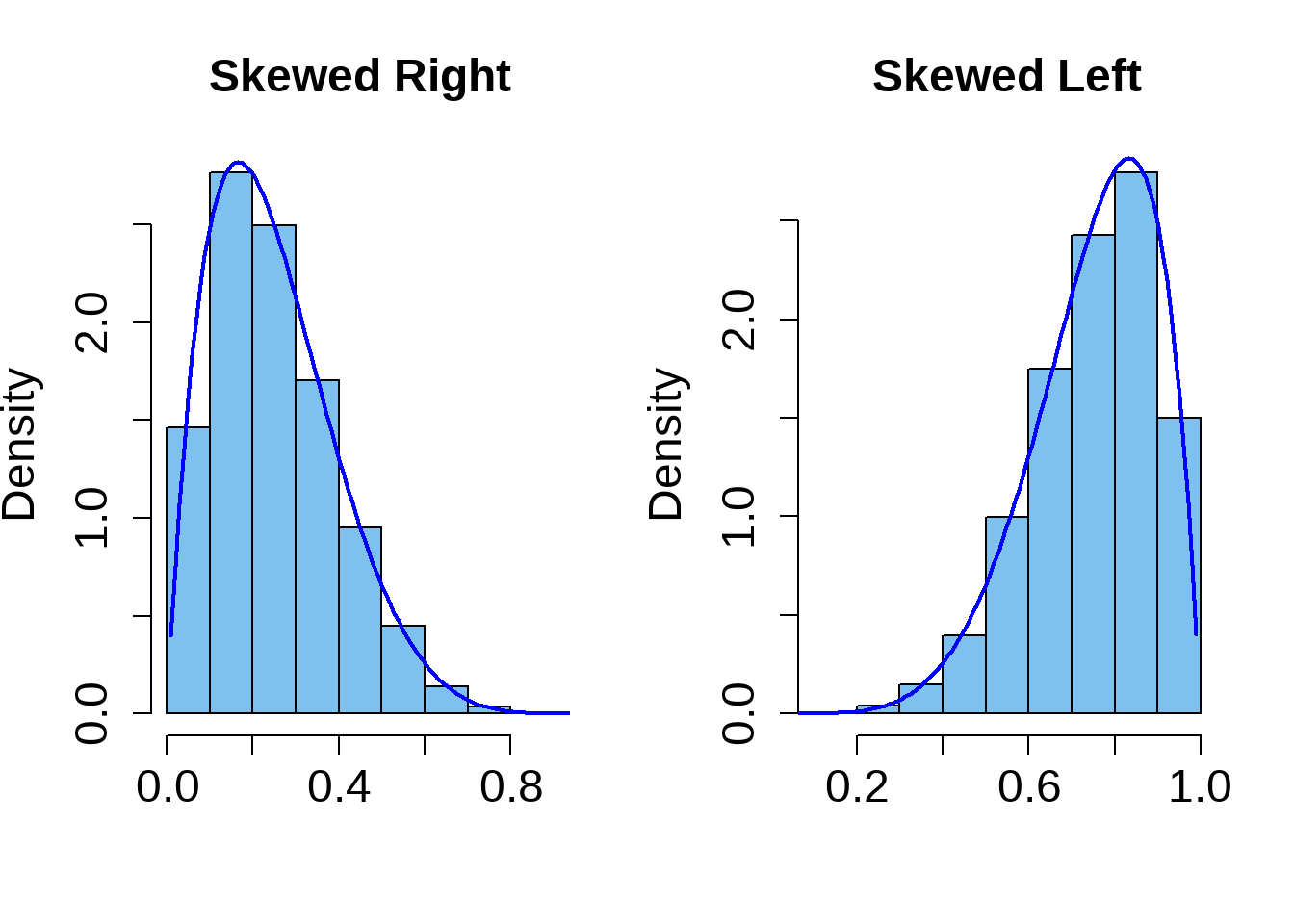
Skew
- A histogram is skewed right if the longer tail is on the right side of the mode.
- A histogram is skewed left if the longer tail is on the left side of the mode.
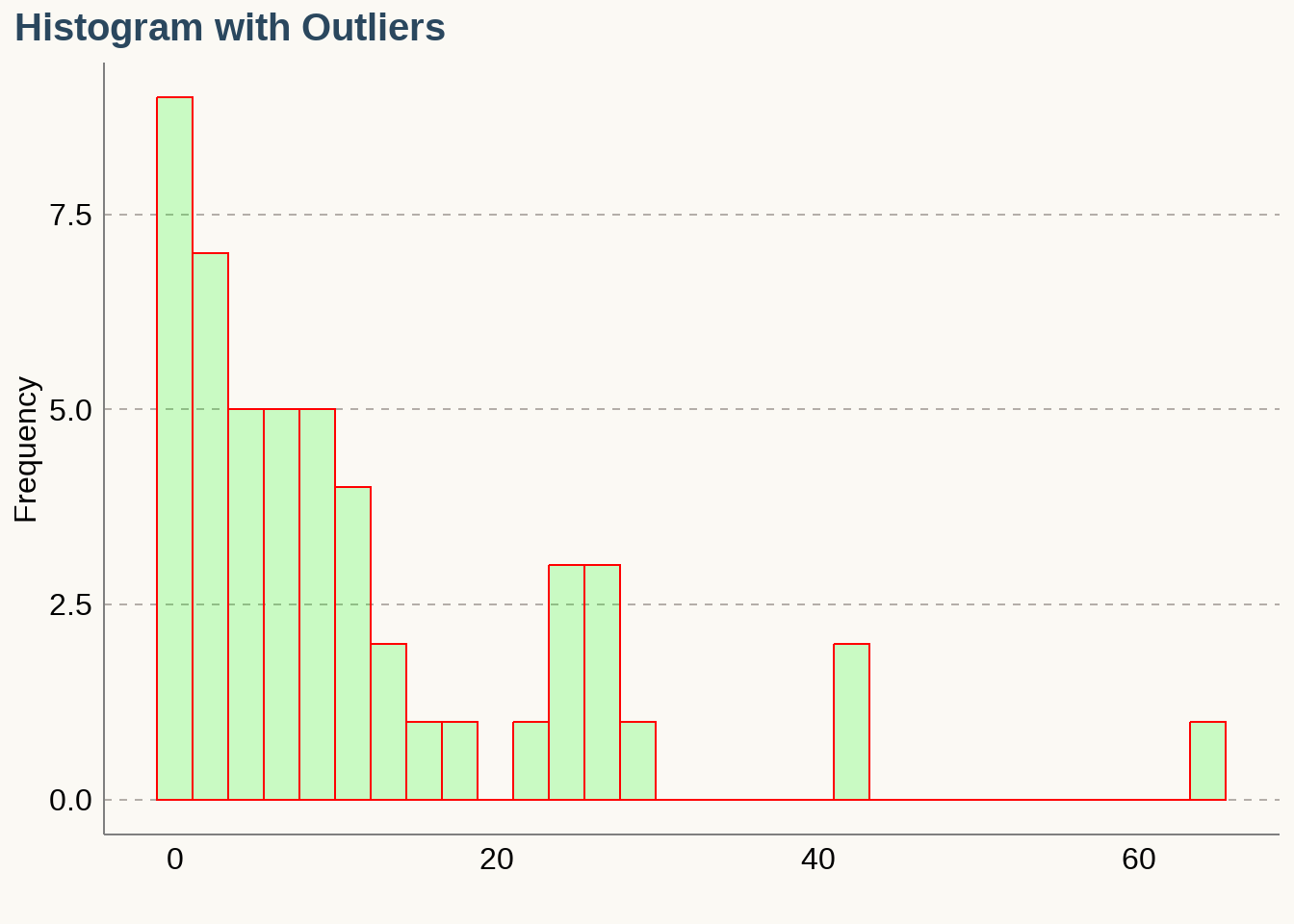
Outlier
- An Outlier is a data value that is far above or far below the rest of the data values.
4.2 Measures of Center
Mean
The sample mean of a numerical variable is computed as the sum of all of the observations \(\{x_1, x_2, \cdots, x_n\}\) divided by the number of observations \((n)\).
If \(\bar x\) is the mean, then
\[ \displaystyle (\bar x - x_1) + (\bar x - x_2) + \cdots + (\bar x - x_n) = 0 \\ \displaystyle \text{Therefore}, \ \bar x = \frac{(x_1+x_2+...+x_n)}{n} = \dfrac{1}{n}\sum_{i=1}^n x_i \]
The mean follows the tail
- In a right skewed distribution, the mean is greater than the median.
- In a left skewed distribution, the mean is less than the median.
- In a symmetric distribution, the mean and median are approximately equal.
Median
The median splits an ordered data set in half. If there are an even number of observations, the median is the average of the two middle values. If there are an odd number of observations, the median is the middle value.
0 0 0 0 0 0 1 1 1 1
1 2 2 3 3 3 4 4 5 5
5 6 6 7 7 7 9 9 9 10
10 10 11 11 12 14 14 16 17 22
25 25 25 26 26 27 29 42 43 64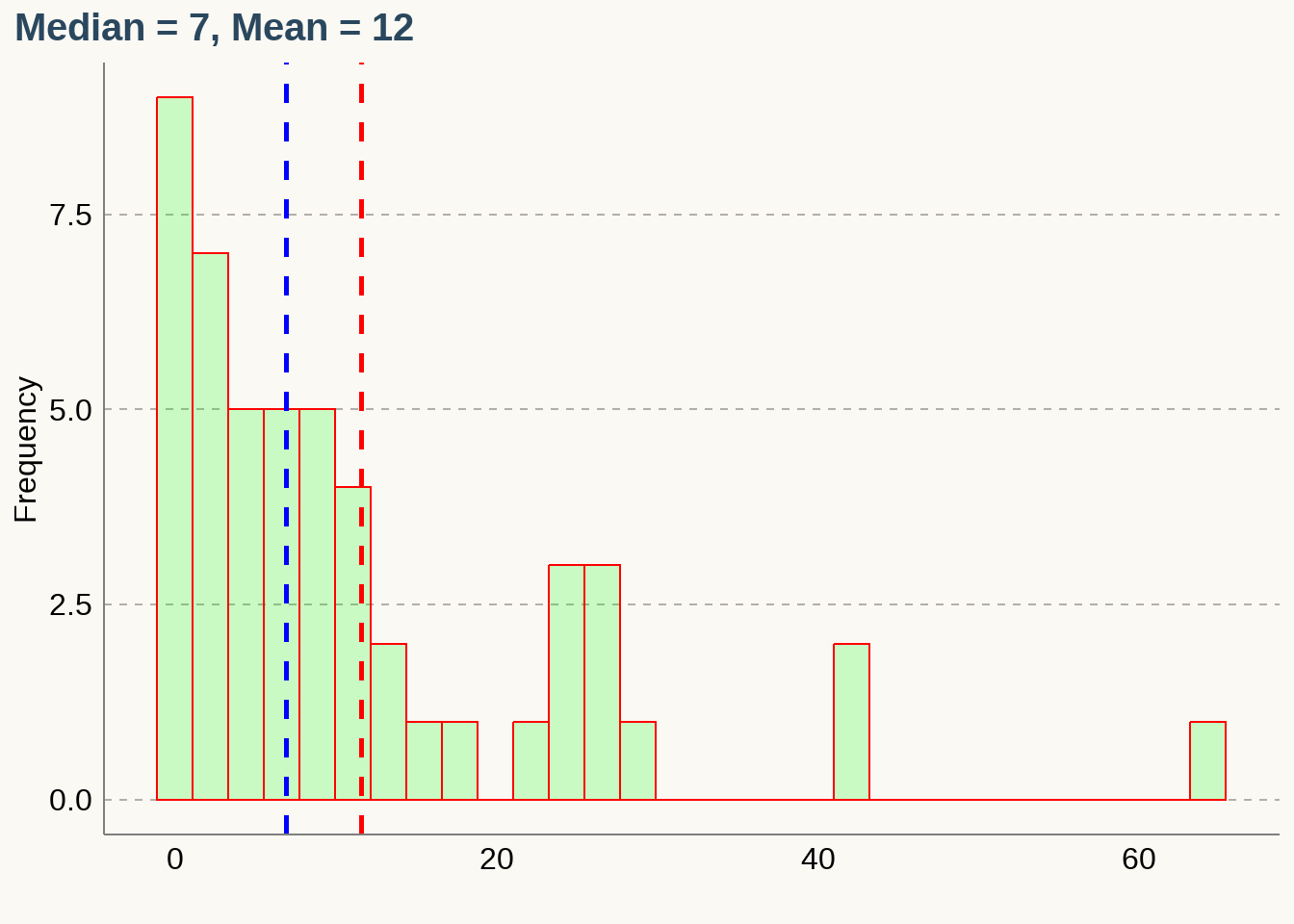
Calculating the Median
\(n\) is odd
- Sort the series in ascending order.
- If the series has odd number \((n)\) of entries, the median is at position
\(x_1, \cdots, \underbrace{x_{\frac{n+1}{2}}}, \cdots, x_n.\)
- Find the median of the series: \(2,4,5,(6),7,9,9\)
- The median is \(6\).
\(n\) is even
- Sort the series in ascending order.
- If the series has even number \((n)\) of entries, the median is the average of the two middle numbers:
\(x_1, \cdots, \underbrace{x_{\frac{n}{2}}, x_{\frac{n}{2}+1}}_{ \frac{1}{2}\big(x_{\frac{n}{2}} + x_{\frac{n}{2}+1} \big)}, \cdots, x_n.\)
- Find the median of the numbers: \(\{2,2,4,6,7,8\}\)
- Median is the average of the third and the fourth numbers: \(\dfrac{4+6}{2}=5\)
Example: Comparing the Medians of Two Distributions
\[ \begin{array}{lclc} \text{Pacific State} & \text{Minimum Wage} & \text{Mountain State} & \text{Minimum Wage} \\ \hline \text {Alaska} & 7.75 & \text {Arizona} & 7.90 \\ \text {California} & 8.00 & \text {Colorado} & 8.00 \\ \text {Hawaii} & 7.25 & \text {Idaho} & 7.25 \\ \text {Oregon} & 9.10 & \text {Montana} & 7.90 \\ \text {Washington} & 9.32 & \text {Nevada} & 8.25 \\ & & \text {New Mexico} & 7.50 \\ & & \text {Utah} & 7.25 \\ & & \text {Wyoming} & 5.15 \\ \end{array} \]
Find the median minimum wages of the Pacific and Mountain states.
How the Shape of a Distribution Affects the Mean and the Median
If a distribution is skewed left, the mean is usually less than the median and the median is usually a better measure of the center.
If a distribution is symmetric, the mean is approximately equal to the median and both are reasonable measures of the center.
If a distribution is skewed right, the mean is usually greater than the median and the median is usually a better measure of the center.
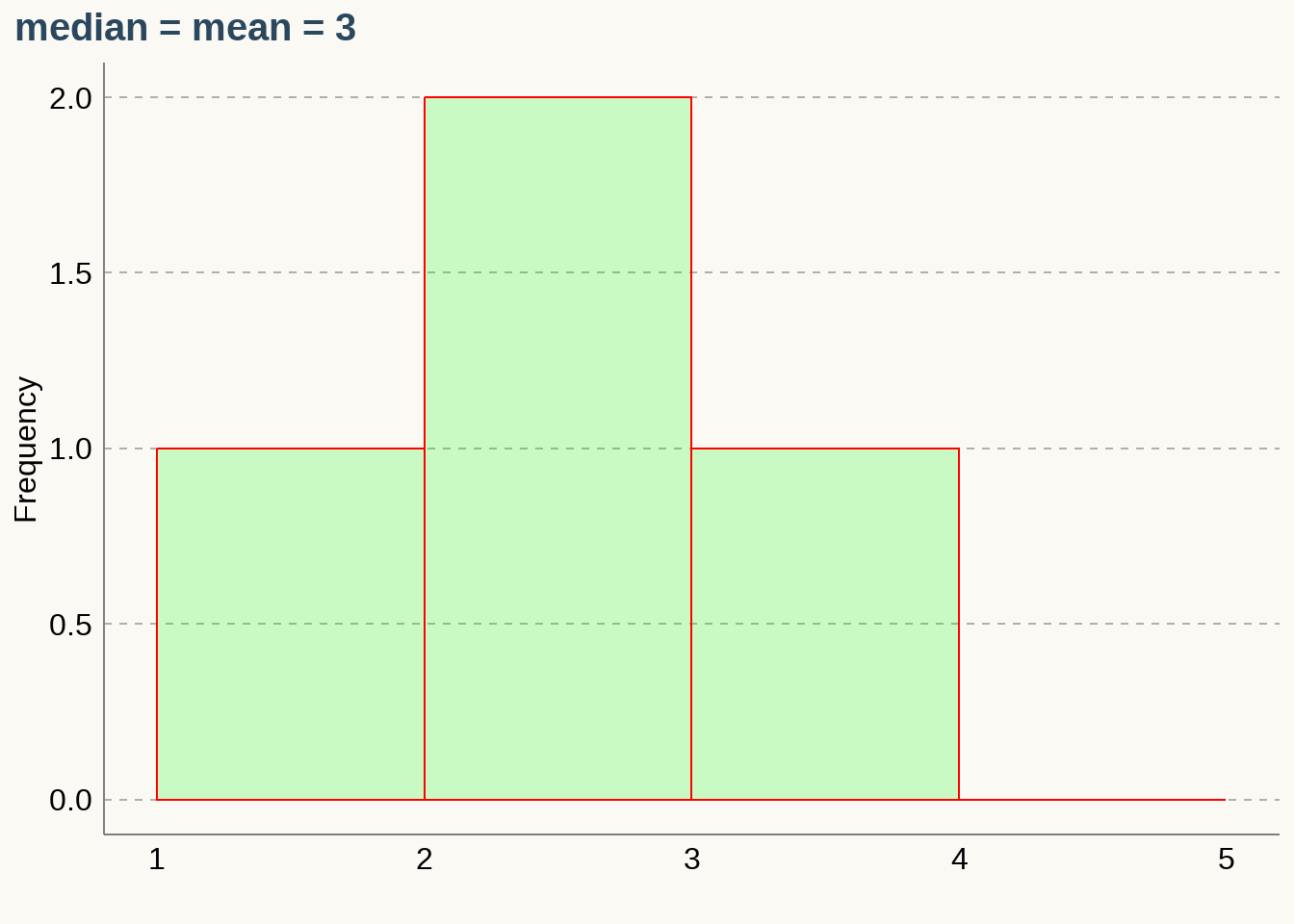
List: \(\{2,3,3,4\}\)
List: \(\{2,3,3,7\}\)
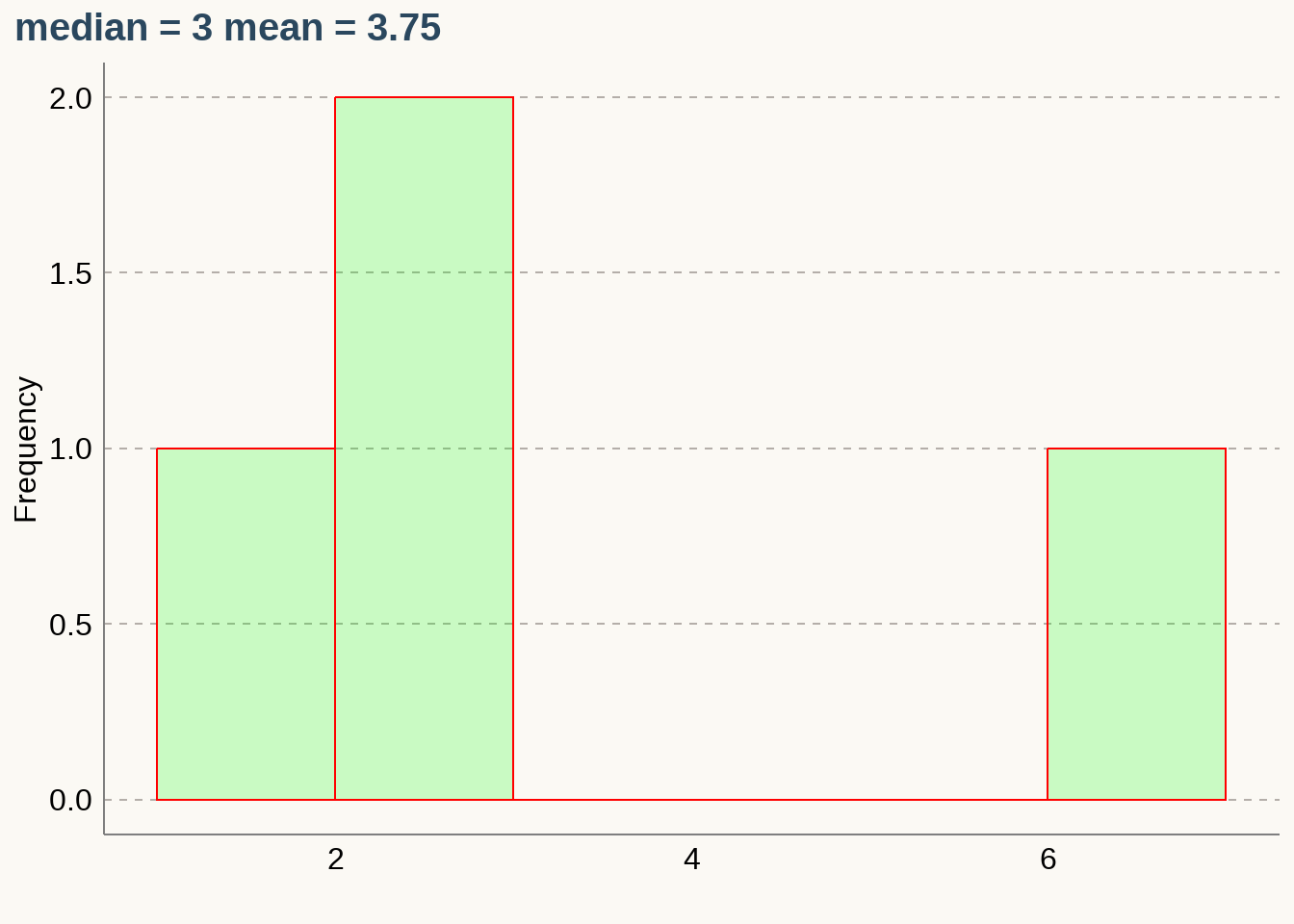
\(\textbf {Notice: The median is unaffected by outliers.}\)
Weighted Mean
The weighted mean is the same as the mean, except that it is influenced more by some observations than others. We assign weights to observations as a sort of way of describing its relative importance.
The weighted mean of observations \(x_1, x_2,...,x_n\) using weights \(w_1, w_2,...,w_n\) is given by
\(\displaystyle \bar x =\frac{w_1x_1+w_2x_2+...+w_nx_n}{w_1+w_2+...+w_n}\)
The simple mean is a weighted mean where all the weights are \(1\).
\(\displaystyle \bar x =\frac{1\times x_1+1\times x_2+...+1\times x_n}{1+1+...+1} = \frac{x_1+x_2+...+x_n}{n}\)
Example 1:
The chart below shows ratings from \(10\) visitors on a \(0-5\) scale. What is the average rating?

\[ \begin{align} &\text{Method 1: } \dfrac{4 + 1 + 3 + 5 + 3 + 5 + 2 + 5 + 5 + 4}{10} = 3.7 \\ \\ &\text{Method 2: } \dfrac{(1)1 + (1)2 + (2)3 + (2)4 + (4)5}{10} = 3.7 \\ \end{align} \]
Example 2: The consumer price index (CPI) is a weighted average of the change in prices paid by consumers for a representative set of goods and services. Use the table to calculate the CPI from March 2008 to March 2009. Round to the nearest tenth of a percent.
\[ \begin{array}{l|c|r} \text{Category} & \text{Weight} & \text{Percent Change} \\ \hline \text{food and beverages} & 16\% & 4.3 \\ \text{housing} & 43\% & 1.4 \\ \text{apparel} & 4\% & 1.4 \\ \text{transportation} & 15\% & -13.1 \\ \text{medical care} & 6\% & 2.8 \\ \text{recreation} & 6\% & 1.7 \\ \text{education and communication } & 6\% & 3.6 \\ \text{other} & 4\% & 5.7 \\ \hline \end{array} \]
Calculating Mean from a Frequency Distribution
\[ \bar x = \dfrac{\sum (f \cdot x)}{\sum f} \]
where, \(f\) is the class frequency and \(x\) is the class midpoint.
\[ \bbox[white,4px] { \color{black} { \begin{array}{c|c|c|c} \text{Time(Seconds)} & \text{Frequency } f & \text{Class Midpoint } x & f \cdot x \\ \hline \text{75-124} & 11 & 99.5 & 1094.5 \\ \text{125-174} & 24 & 149.5 & 3588.0 \\ \text{175-224} & 10 & 199.5 & 1995.0 \\ \text{225-274} & 3 & 249.5 & 748.5 \\ \text{275-324} & 2 & 299.5 & 599.0 \\ \hline \text{Total} & \sum f = 50 & & \sum(f \cdot x) = 8025.0 \\ \end{array} } } \]
\[ \displaystyle \bar x = \dfrac{\sum (f \cdot x)}{\sum f} = \dfrac{8025.0}{50} = 160.5 \]
Midrange
The midrange of a data set is the measure of center that is the value midway between the maximum and minimum values in the original data set. It is found by adding the maximum data value to the minimum data value and then dividing the sum by \(2\), as the following formula:
\[ \text {Midrange} = \dfrac{\text{maximum data value + minimum data value}}{2} \]
4.3 Measures of Spread or Variation
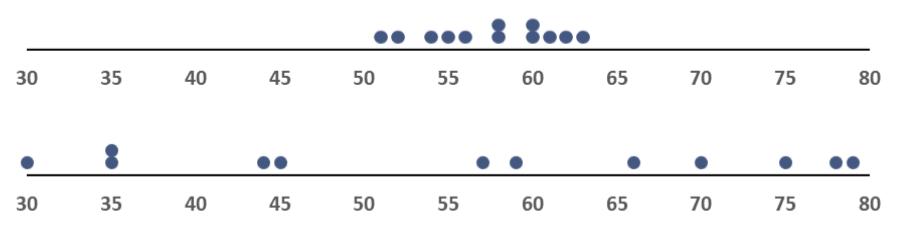
Range
The range of a set of data is the difference between the maximum and the minimum data values.
\(\textbf {range = maximum - minimum}\)
The range is sensitive to outliers. A single high or low value will affect the range significantly.
Standard Deviation of a Sample
- SD \((s)\) of a set of sample values is a measure of how much, on average, the data values deviate away from the sample mean.
- In other word, SD describes the variability of the data set within the range of the dataset.
- Low variability or small spread means that the values tend to be more clustered together.
- High variability or large spread means that the values tend to be far apart.
Calculating the Standard Deviation
The standard deviation is the square root of the variance. It is roughly the average distance of the observations from the mean.
\[ \bbox[yellow,5px] { \color{black}{s= \sqrt{\frac{1}{n-1}\sum(x_i-\bar x)^2}} } \]
Exercise:
\(1. Calculate \space SD \space of \space [0,1]\)
\(2. Calculate \space SD \space of \space [30,20, 41, 21]\)
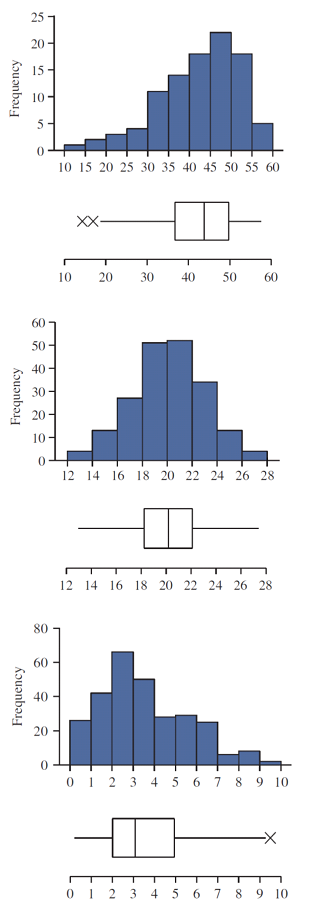
Which histogram has the largest SD?
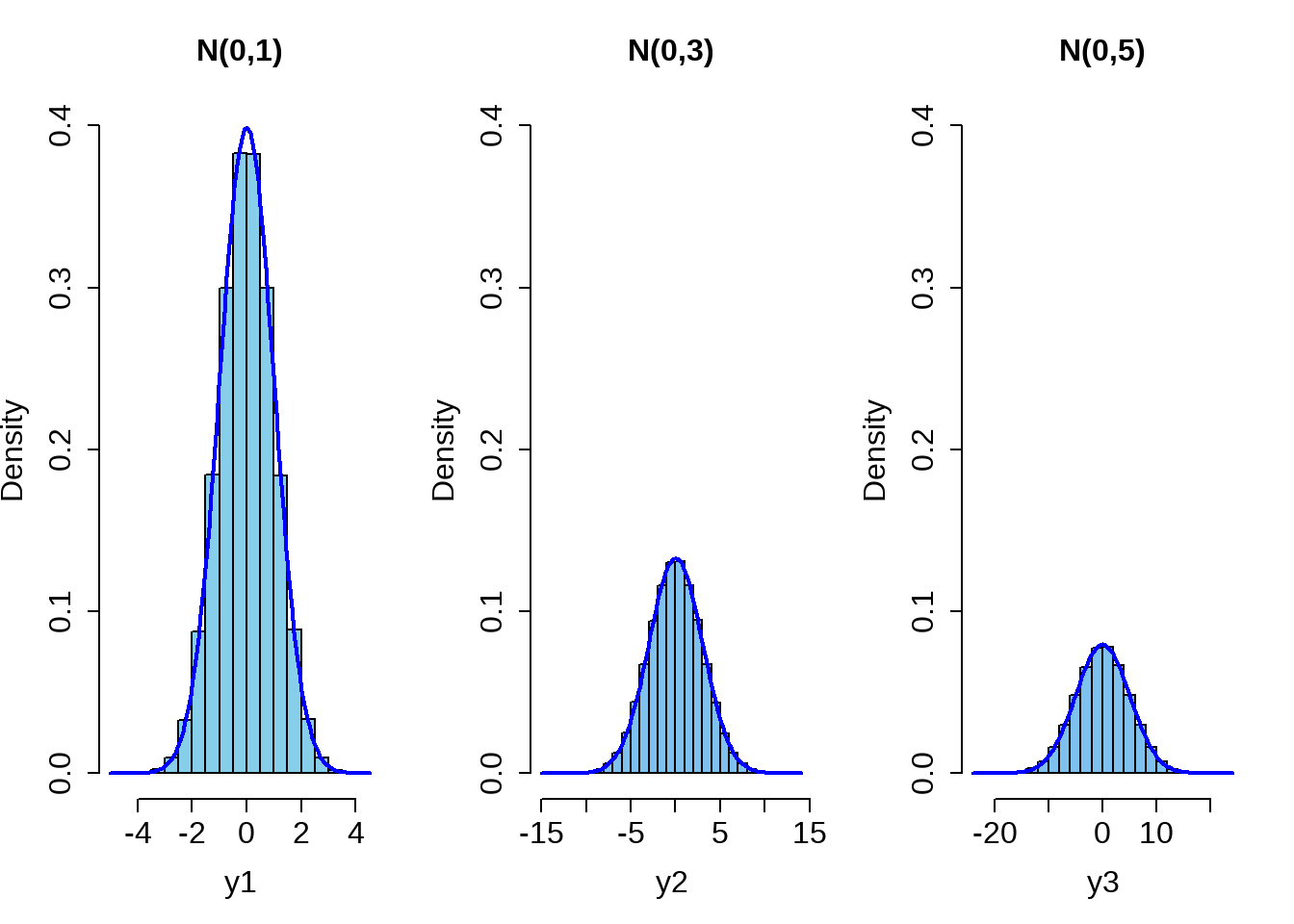
Hint: pay attention to the range of the distributions.
Calculating Standard Deviation from a Frequency Distribution
\(\text {Step 1: Calculate weighted average from the class midpoint and class frequency}\)
\[ \bar x = \dfrac{\sum (f \cdot x)}{\sum f} \]
where, \(f\) is the class frequency and \(x\) is the class midpoint.
\[ \bbox[white,4px] { \color{black} { \begin{array}{c|c|c|c} \text{Time(Seconds)} & \text{Frequency } f & \text{Class Midpoint } x & f \cdot x \\ \hline \text{75-124} & 11 & 99.5 & 1094.5 \\ \text{125-174} & 24 & 149.5 & 3588.0 \\ \text{175-224} & 10 & 199.5 & 1995.0 \\ \text{225-274} & 3 & 249.5 & 748.5 \\ \text{275-324} & 2 & 299.5 & 599.0 \\ \hline \text{Total} & \sum f = 50 & & \sum(f \cdot x) = 8025.0 \\ \end{array} } } \]
\[ \displaystyle \bar x = \dfrac{\sum (f \cdot x)}{\sum f} = \dfrac{8025.0}{50} = 160.5 \]
\(\text {Step 2: Calculate variance}\)
\[ \displaystyle s^2 = \dfrac{1}{\sum_{i} f_i - 1}\sum_{i} f_i(x_i - \bar x)^2 \]
\[ \bbox[white,4px] { \color{black} { \begin{array}{c|c|c|c} \text{Time(Seconds)} & \text{Frequency } f & \text{Class Midpoint } x & f_i \cdot(x_i - \bar x)^2 \\ \hline \text{75-124} & 11 & 99.5 & 40931 \\ \text{125-174} & 24 & 149.5 & 2904 \\ \text{175-224} & 10 & 199.5 & 15210 \\ \text{225-274} & 3 & 249.5 & 23763 \\ \text{275-324} & 2 & 299.5 & 38642 \\ \hline \text{Total} & \sum f = 50 & & \sum f_i \cdot (x_i - \bar x)^2 = 121450 \\ \end{array} } } \]
\[ \begin{align} s^2 &= \dfrac{121450}{50-1} = 2478.6 \\ \end{align} \]
\(\text {Step 3: Calculate standard deviation}\)
\[ \begin{align} s &= \sqrt {2478.6} = 49.8 \end{align} \]
Standard Deviation of a Population
\[ \bbox[yellow,5px] { \color{black}{\sigma= \sqrt{\frac{1}{N}\sum(x_i-\mu)^2}} } \]
Variance of a Sample and Population
The variance of a set of values is a measure of variation equal to the square of the standard variation.
- Sample variance: \(s^2 =\) square of the sample standard deviation \(s\).
- Population variance: \(\sigma^2 =\) square of the population standard deviation \(\sigma\).
Why is \((n-1)\) used to calculate standard deviation?
\(\acute s = \sqrt{\frac{1}{n}\sum(x_i-\bar x)^2}\) is not an unbiased estimator of the population standard deviation \(\sigma\), meaning that the distribution of \(\acute s\) does not tend to center around \(\sigma\). Therefore, an adjustment is applied by replacing \(n\) by \((n-1)\) in the denominator.
\(s = \sqrt{\frac{1}{n-1}\sum(x_i-\bar x)^2}\) is an unbiased estimator of \(\sigma\).
Also, with division by \(n-1\), sample variance \(s^2\) tend to center around the value of the population variance \(\sigma^2\); with division by \(n\), sample variances \(s^2\) tend to underestimate the value of the population variance \(\sigma^2\).
Coefficient of Variation
The coefficient of variation (CV) for a set of non-negative sample or population data, expressed as a percent, describes the standard deviation relative to the mean, and is given by the following:
\[ Sample: CV = \frac{s}{x}.100 \\ Population: CV = \frac{\sigma}{x}.100 \]
\(CV\) is useful compare the spreads of multiple distributions. Suppose, you are looking for a safe investment option among stocks, EFTs, and bonds.
\[ \text {CV =} \dfrac{\text{volatility } (\sigma)}{\text {expected return } (\mu)} \times 100 \% \]
\[ \text {CV (Stocks) =} \dfrac{11\%}{15\%} \times 100 \% = 73.3\% \\ \text {CV (EFT) =} \dfrac{9\%}{13\%} \times 100 \% = 69.2\% \\ \text {CV (Bonds) =} \dfrac{2\%}{3\%} \times 100 \% = 66.7\% \\ \]
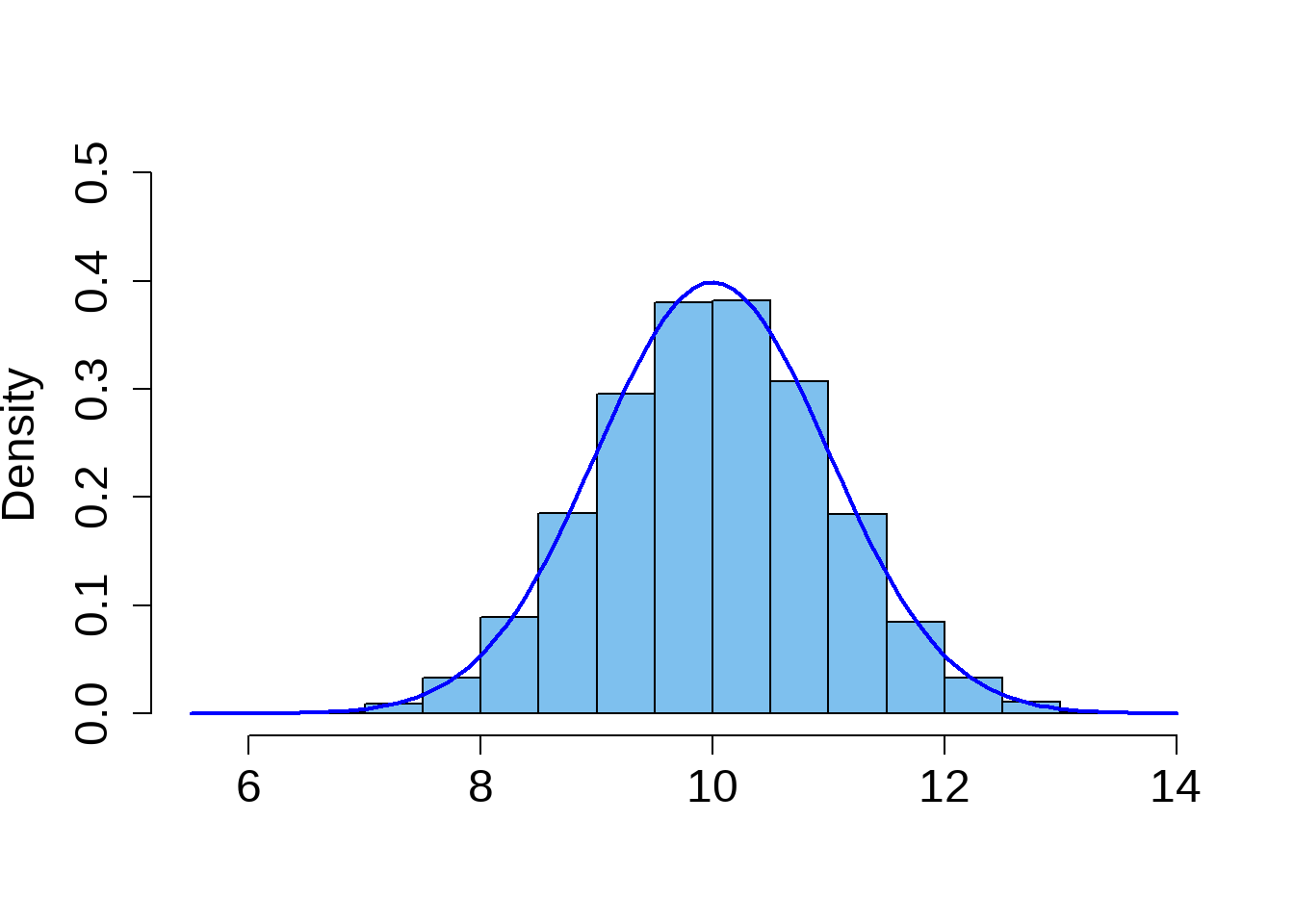
4.4 The Empirical Rule
When a data set has a bell-shaped histogram (or normal distribution), it is often possible to use the standard deviation to provide an approximate description of the data using a rule known as The Empirical Rule.
Empirical Rule of Normal Distribution
\[ \begin{array}{lc} \text{Interval} & \text{Percent} \\ \hline \mu \pm \sigma & 68 \% \\ \mu \pm 2\sigma & 95 \% \\ \mu \pm 3\sigma & 99.7 \% \\ \hline \end{array} \]
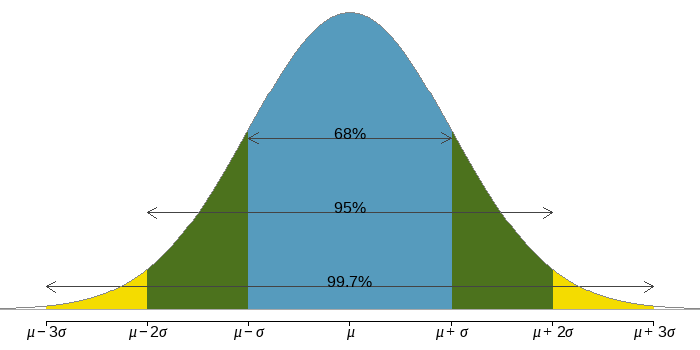
Example:
A large class of \(200\) students took an exam. The scores had sample mean and sample standard deviation \(s = 10\). The histogram is approximately normally distributed. Approximately how many students had scores between \(45\) and \(85?\)
Solution:
The value \(45\) is two standard deviations below the mean since
\(\bar x - 2s = 65 - 20 = 45\)
and the value \(85\) is two standard deviations above the mean since
\(\bar x + 2s = 65 + 20 = 85\)
By the Empirical Rule, approximately \(95\%\) of scores are between \(45\) and \(85\).
There were \(200\) students in the class. Therefore, the number that had scores between \(45\) and \(85\) is approximately \((0.95)(200) = 190\).
4.4.1 Chebyshev’s Inequality
When a distribution is bell-shaped, we use the Empirical Rule to approximate the proportion of data within one or two standard deviations of the mean. Another rule called Chebyshev’s Inequality holds for any data set.
In any data set, the proportion of the data that is within \(K\) standard deviations of the mean is at least \(1 - (1/K^2)\). Specifically, by setting \(K = 2\) or \(K = 3\), we obtain the following results.
At least \(3/4\), or \(75\%\), of the data are within two standard deviations of the mean.
At least \(8/9\), or \(89\%\), of the data are within three standard deviations of the mean.
Example:
As part of a public health study, systolic blood pressure was measured for a large group of people. The mean was \(120\) and the standard deviation was \(10\). What information does Chebyshev’s Inequality provide about these data?
Solution:
We compute the following:
\[\bar x - 2s = 120 - 2(10) = 100 \\ \bar x + 2s = 120 + 2(10) = 140\]
At least \(3/4\) \((75\%)\) had systolic blood pressures between \(100\) and \(140\).
\[\bar x - 3s = 120 - 3(10) = 90 \\ \bar x + 3s = 120 + 3(10) = 150\]
At least \(8/9\) \((89\%)\) had systolic blood pressures between \(90\) and \(150\).
4.5 Z-Score
A z-score (or standard score or standardized value) is the number of standard deviations that a given value \(x\) is above or below the mean. The \(z\) score is calculated by using one of the following:
\[z= \dfrac{x-\bar x}{s}\]
\[ \begin{align} x = \bar x - 2s &\implies z = -2 \\ x = \bar x - s &\implies z = -1 \\ x = \bar x &\implies z = 0 \\ x = \bar x + s &\implies z = +1 \\ x = \bar x + 2s &\implies z = +2 \\ \end{align} \]
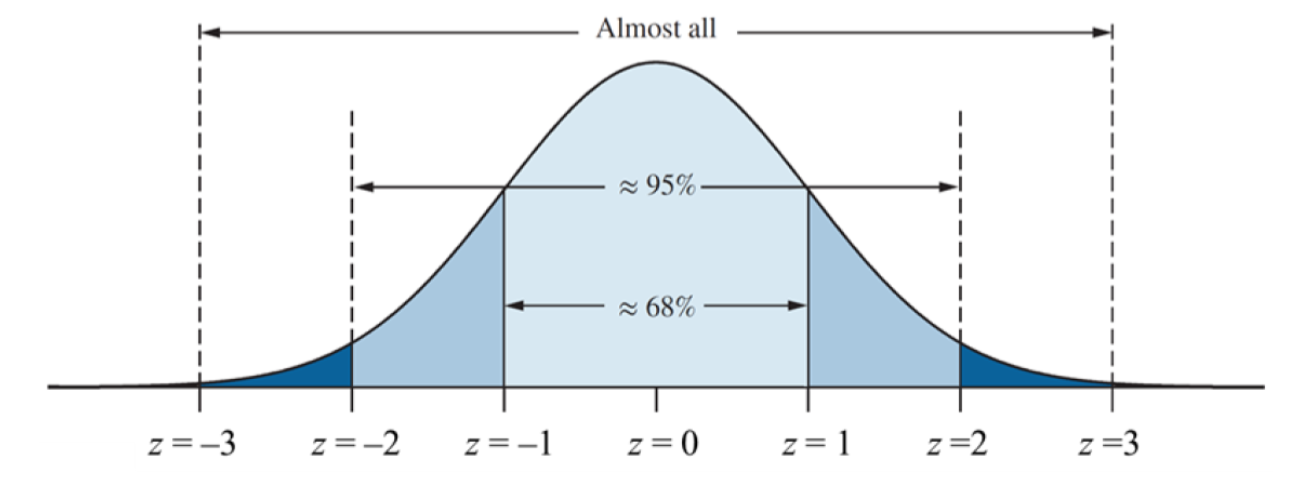
Note: \(z\)-score is useful in comparing two variables measured on different scales.
Example: A National Center for Health Statistics study states that the mean height for adult men in the U.S. is \(\mu = 69.4\) inches, with a standard deviation of \(\sigma = 3.1\) inches. The mean height for adult women is \(\mu = 63.8\) inches, with a standard deviation of \(\sigma = 2.8\) inches. Who is taller relative to their gender, a man \(73\) inches tall, or a woman \(68\) inches tall?
Solution:
\[ z_{\text {men's height}} = \dfrac{x - \mu}{\sigma} = \dfrac{73 - 69.4}{3.1} = 1.16 \\ z_{\text {women's height}} = \dfrac{x - \mu}{\sigma} = \dfrac{68 - 63.8}{2.8} = 1.50 \\ \] \(\therefore\) the woman is taller, relative to the population of women’s heights.
Example: Finding A Value with a Given Z-Score
Data from the National Health and Examination survey estimate the mean total cholesterol level, in milligrams per deciliter, in the adult population to be \(\mu = 200\), with a standard deviation of \(\sigma = 44\). What is the cholesterol level of a person with a z-score of \(1.5?\)
Solution:
The cholesterol level for the person with a z-score of \(1.5\) is \(1.5\) standard deviations above the mean. This person’s cholesterol level is:
\[x = \mu + z \sigma = 200 + 1.5(44) = 266\]
4.6 Percentiles and Quartiles
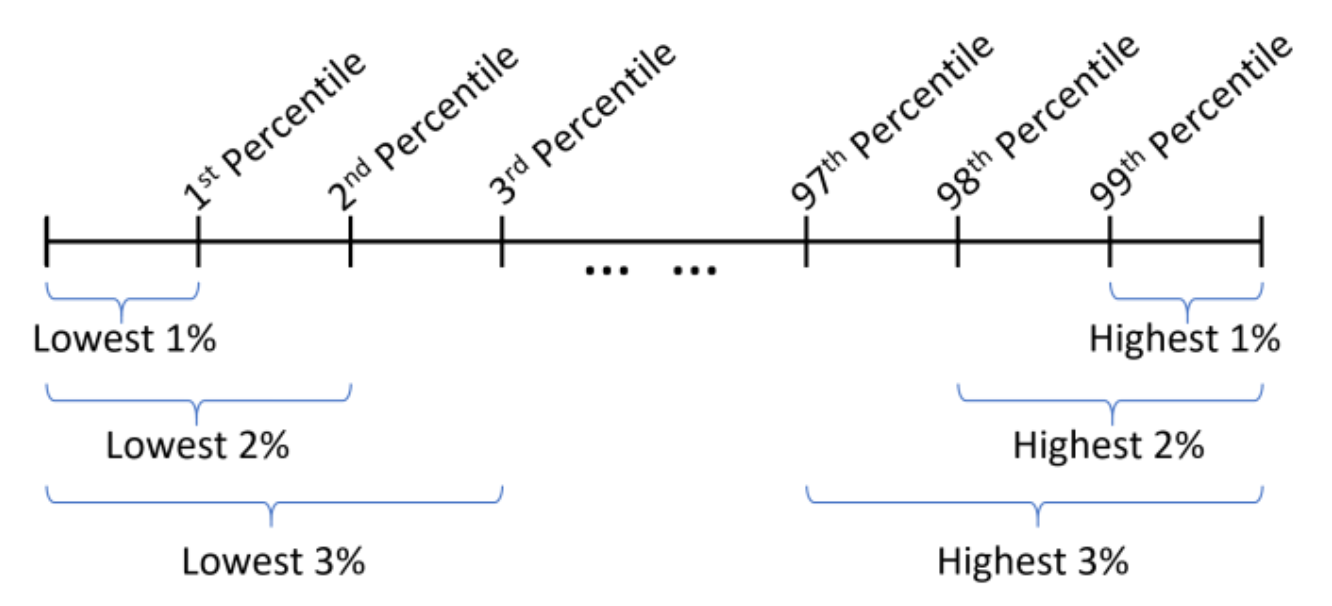
- Percentiles are measures of location, denoted \(P_1, P_2, \cdots, P_{99}\), which divide a set of data into \(100\) groups with about \(1\%\) of the values in each group.
- Example - the \(50th\) percentile, denoted \(P_{50}\) has about \(50\%\) of the data values below it.
- The \(n^{th}\) percentile is the data value such that \(n\) percent of the data lies below that value.
\[ \text{Percentile of value } x = \frac{\text{number of values less than } x}{\text{total number of values}} \times 100 \]
Finding a Percentile
\(\text {Table: (Sorted) Verizon Airport Data Speeds (Mbps)}\)
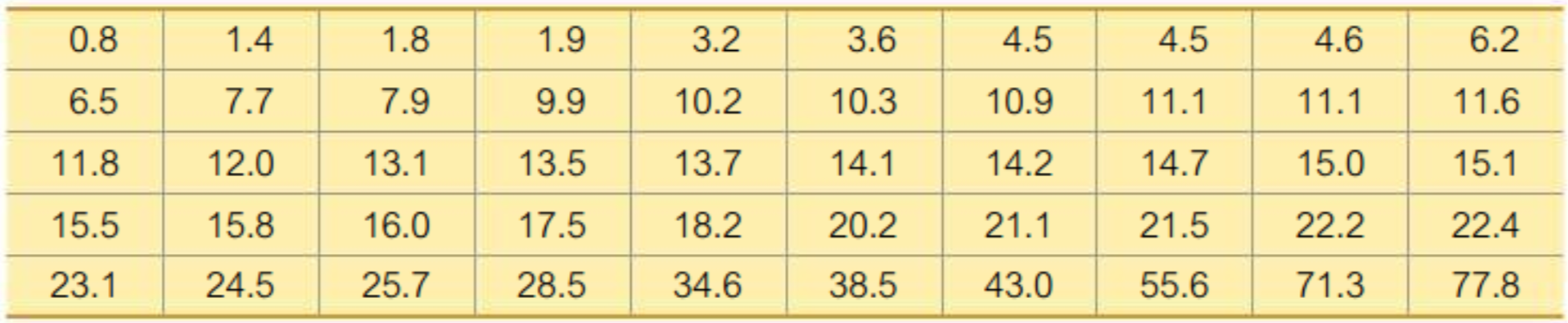
Find the percentile for the data of \(11.8\) mbps.
There are \(50\) data speeds in the table. There are \(20\) data speeds less than \(11.8\) mbps.
\(\therefore\) percentile of \(11.8 = \dfrac{20}{50} \cdot 100 = 40\)
Interpretation: A data speed of \(11.8\) mbps is in the \(40\)th percentile. This means \(40\%\) of the airports reported data speeds less than \(11.8\) mbps.
Find the \(40th\) percentile.
First, compute the locator, \(L = \dfrac{k}{100} \cdot n = \dfrac{40}{100} \cdot 50 = 20.\) By definition, \(P_{40}\) below which \(40\%\) of the data points fall. Hence, the \(40\)th percentile is midway between the \(20\)th and \(21\)st value. In the table above, \(20th\) value is \(11.6\) and \(21\)st value is \(11.8\), so the midway between them is \(11.7\) mbps.
\(\therefore P_{40} = 11.7\) mbps.
Note: in some references, a percentile value is chosen from the existing data. Therefore, the \(21st\) data point \(11.8\) can also be considered the \(40th\) percentile value. This answer is consistent with the previous example.
Find the \(25th\) percentile.
\(L = \dfrac{k}{100} \cdot n = \dfrac{25}{100} \cdot 50 = 12.5.\)
In this case, we round up the value of \(L\) to get \(13\) to make sure at least \(12.5\) data points fall below that point.
\(\therefore P_{25} = 7.9\) mbps.
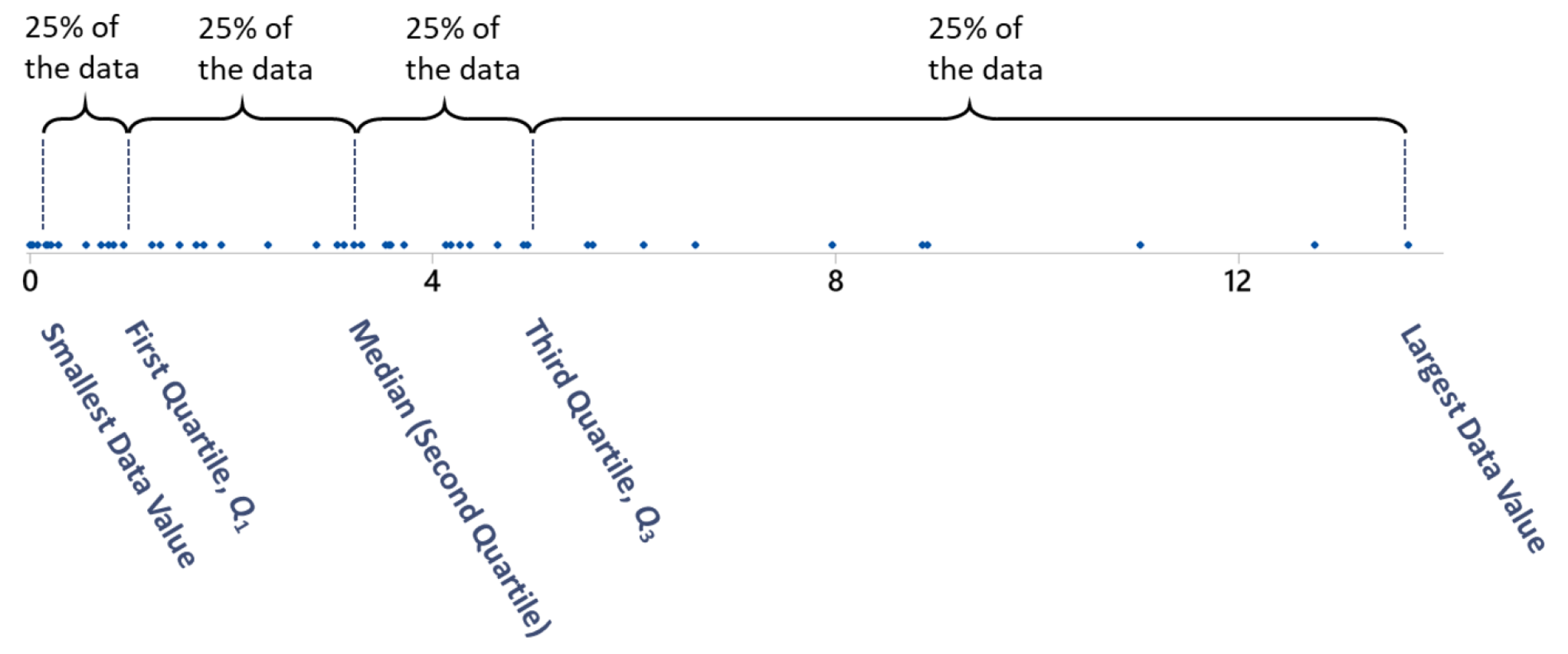
Three Quartiles \((Q_1, Q_2, Q_3)\)
- \(Q_1\) represents the first quartile, which is the 25th percentile, and is the median of the smaller half of the data set.
- \(Q_2\) represents the second quartile, which is equivalent to the 50th percentile (i.e. the median).
- \(Q_3\) represents the third quartile, or 75th percentile, and is the median of the larger half of the data set
- Interquartile Range \((IQR) = Q_3 - Q_1\)
4.7 Boxplot
5-Number Summary
For a set of data, the 5-number summary consists of five values:
- minimum
- first quartile, \(Q_1\)
- second quartile (median), \(Q_2\)
- third quartile, \(Q_3\)
- Maximum
A boxplot (or box-and-whisker diagram) is a graph of a data set that consists of a line extending from the minimum value to the maximum value, and a box with lines drawn at the first quartile \((Q_1)\), the median \((Q_2)\), and the third quartile \((Q_3)\).
Outlier and Fences
When in the context of a box plot, define an outlier as an observation that
right fence: \[ Q_3 + 1.5 \times IQR < \text {outlier} \]
left fence: \[ \text {outlier} < Q_1 - 1.5 \times IQR \]
Such points are marked using a dot or asterisk in a box plot.
Example:
Data: \([5, 5, 9, 10, 15, 16, 20, 30, 40]\)
\[ \text{Q}_1 = 9 \\ \text{Q}_2 = 15 \\ \text{Q}_3 = 20 \\ \text{IQR} = 20 - 9 = 11 \\ \text{LF} = \text{Q}_1 - 1.5 \times \text{IQR} = -7.5 \\ \text{UF} = \text{Q}_3 + 1.5 \times \text{IQR} = 36.5 \\ \]
Five Number Summary:
Min. 1st Qu. Median Mean 3rd Qu. Max.
5.00 9.00 15.00 16.67 20.00 40.00 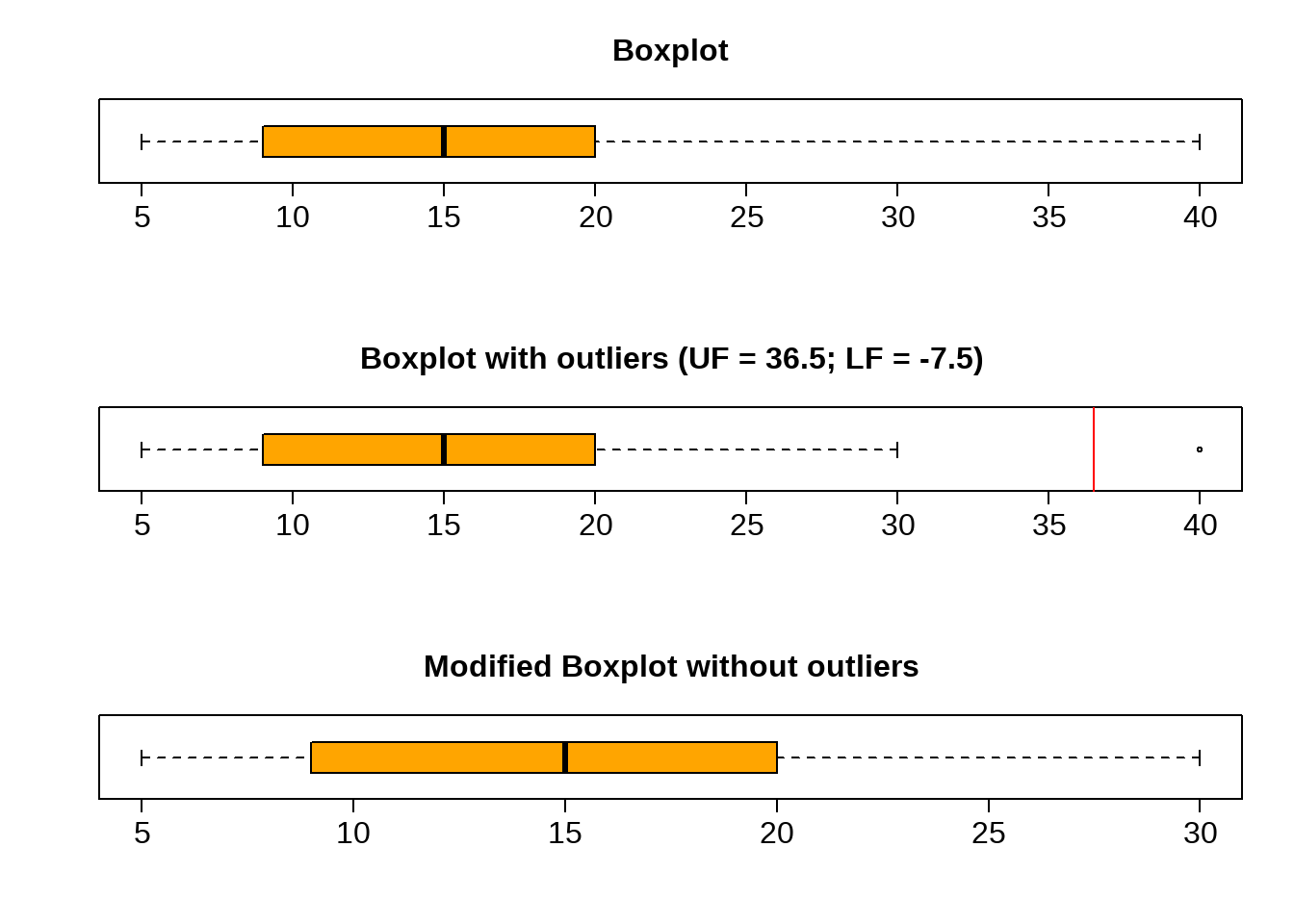
Exercise: Drawing a Boxplot with an Outlier
Students in one of the author’s statistics classes were surveyed about the number of novels they read in the past year. Here are the anonymous responses (in numbers of novels) of 11 of the students:
\([2, 5, 2, 0, 2, 3, 0, 5, 6, 4, 12]\)
- Construct a boxplot.
- Check if there is any outlier.