Chapter 2 Introduction
Learning Outcome:
Select a suitable sampling design {simple random, systematic, stratified, cluster}, given information about the observational study or experiment.
The chapter introduces various data types, sampling techniques, sampling errors, two main types of statistical studies, namely observational studies and experiments. Also discussed here are their benefits and drawbacks and how to design them well.
2.1 What is Statistics?
The science of planning studies and experiments; obtaining data; and organizing, summarizing, presenting, analyzing, and interpreting those data and then drawing conclusions based on them.
Application of statistics is literally everywhere - business, finance, engineering, health science, social science, environmental science, politics, education, and so on.
2.2 Statistical Thinking
Statistics is an investigative process that has five steps:
- Formulate a precise question about one or more variables.
- Will the COVID vaccine be effective on children (ages < 5 years)?
- Design a plan to answer the question.
- Construct a theory or hypothesis based on existing knowledge, say laboratory experiments, or similar studies in the past.
- Who will be recruited to the clinical trial (target population)?
- What kind of data needs to be collected (age, sex, medical history, etc.)?
- How the data will be collected (sampling methods)?
- How the privacy of the participants will be protected?
Collect the data.
Describe and analyze the data.
- Analyze the data to test your theory or hypothesis.
- Draw a conclusion from the data about the question and communicate the results with the stakeholders.
Definitions
Data are collections of observations, such as measurements or survey responses.
Variable is a characteristics of the individuals to be measured or observed.
Population is the complete collection of all measurements or data that are being considered. Typically, a population is the complete collection of data that we would like to make inference about.
Census is the collection of data from every member of the population.
Sampling Frame is a numbered list of all the individuals in the population from which a sample is drawn.
Sample is a sub-collection of members selected from a population.
Population Parameter is a numerical measurement describing some characteristics of a population.
Sample Statistic is a numerical measurement describing some characteristics of a sample.
Example (parameter vs. statistic):
There are \(17,246,372\) high school students in the U.S. In a study of \(8505\) U.S. high school students \(16\) years of age or older, \(44.5\%\) of them said that they texted while driving at least once during the previous \(30\) days.
- Parameter: What percent of the population texted while driving? (unknown)
- Statistic: \(44.5\%\)
2.3 Types of Data or Variable
1) Categorical (or Qualitative) - consist of names or labels (not numbers that represent counts or measurements)
Levels of Measurement of Qualitative Data
- Nominal (unordered): the data fall into categories that have no particular order or ranking in relation to each other, e.g.,
color (blue, green, red,…),
gender (male, female),
nationality (American, Canadian, Mexican,…)
- Ordinal (ordered): values have a natural order to ranking, but differences either can’t be found or are meaningless e.g.,
temperature (low, medium, high),
exam grade (A, B, C, D, F),
satisfaction (high, neutral, low)
2) Numerical (or Quantitative) - consist of numbers representing measurements or counts.
- Continuous: a subject or observation takes a value from an interval of real numbers, e.g., weight, height, age, etc. Continuous (numerical) data result from infinitely many possible quantitative values, where the collection of values is not countable, such as the lengths of distances from \(0\) inch to \(12\) inch.
- Discrete: a subject or observation takes certain values from a finite set, e.g. population, traffic volume, etc. Discrete data result when values are quantitative and the number of values is finite, or “countable”, such as the number of tosses of a coin before getting tails.
Levels of Measurement of Quantitative Data
Interval Variables: these variables are measured along a continuum, and they have the property that equal differences between measures represent equal differences in the values of the variable. Therefore, differences are meaningful, but there is no natural zero starting point at which none of the quantity is present and ratios are meaningless. For example, temperature is measured in degrees Celsius. So the difference between \(20^\circ C\) and \(30^\circ C\) is the same as \(30^\circ C\) to \(40^\circ C\). However, \(0^\circ C\) does not mean there is no temperature. Also, \(\dfrac{40^\circ C}{20^\circ C} = 2\) does not mean \(40^\circ C\) is twice the warmer than \(20^\circ C\). Similarly the years 2021 and when you were born, say 1981, can be arranged in order, and the difference of \(40\) years can be found and is meaningful. However, time did not begin in year \(0\), so the year \(0\) is arbitrary instead of being a natural zero starting point representing “no time”.
Ratio Variables: these variables have all the properties of interval variables, but in addition have the property that there is a natural zero starting point (where zero indicates that none of the quantity is present) and the ratios make sense. Examples of ratio variables include height, mass, distance, time etc. The name “ratio” reflects the fact that you can use the ratio of measurements. So, for example, a distance of \(10\) meters is twice the distance of \(5\) meters, and the measurement of distance starts at \(0\).
2.4 Sampling Methods
Sampling from a Population
Because populations are often very large, a common objective of the use of statistics is to obtain data from a sample and then use those data to form a conclusion about the population.
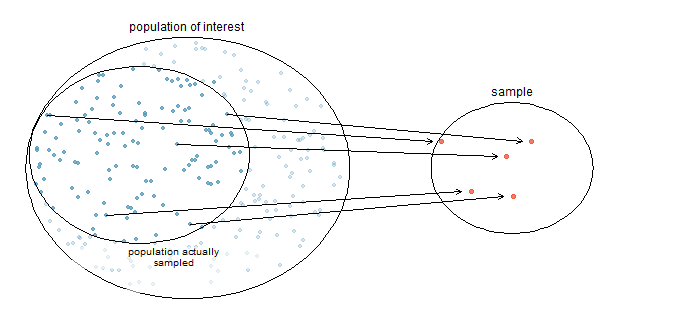
Example: Identify the Variable, Sample, and Population of a Study
In a poll of \(1000\) randomly selected American adults, \(48\%\) of respondents said that they strongly disapprove of the way Congress is doing its job. The study then made an inference about all American adults.
- Define the variable of the study.
- Identify the sample.
- Identify the population.
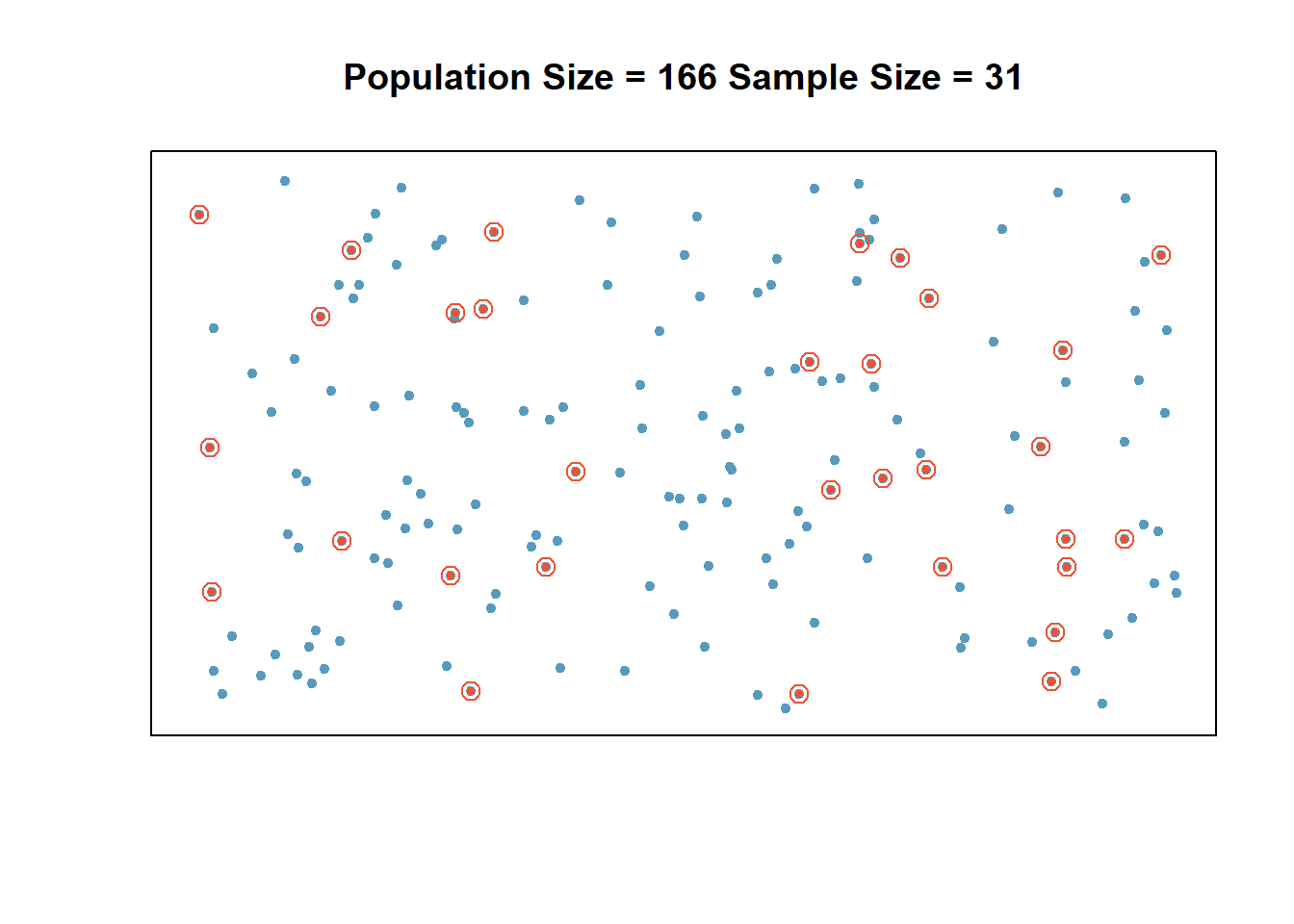
2.4.1 Simple Random Sampling (SRS)
A simple random sample of size \(n\) is a sample chosen by a method in which each collection of \(n\) population items is equally likely to make up the sample.
Example: A physical education professor wants to study the physical fitness levels of \(20,000\) students enrolled at her university. She obtains a list of all \(20,000\) students, numbered from \(1\) to \(20,000\) and uses a computer random number generator to generate 100 random integers between \(1\) and \(20,000\), then invites the \(100\) students corresponding to those numbers to participate in the study. Is this a simple random sample?
Solution: Yes, this is a simple random sample since any group of \(100\) students would have been equally likely to have been chosen. In other words, each student in the group has an equal chance to be part of the sample.
In statistics a sample of a population is said to be random if each member in the population has an equal chance of being chosen.
Sampling with replacement - an individual is selected more than once.
Sampling without replacement - an individual is selected only once.
Source: OpenIntro.Org
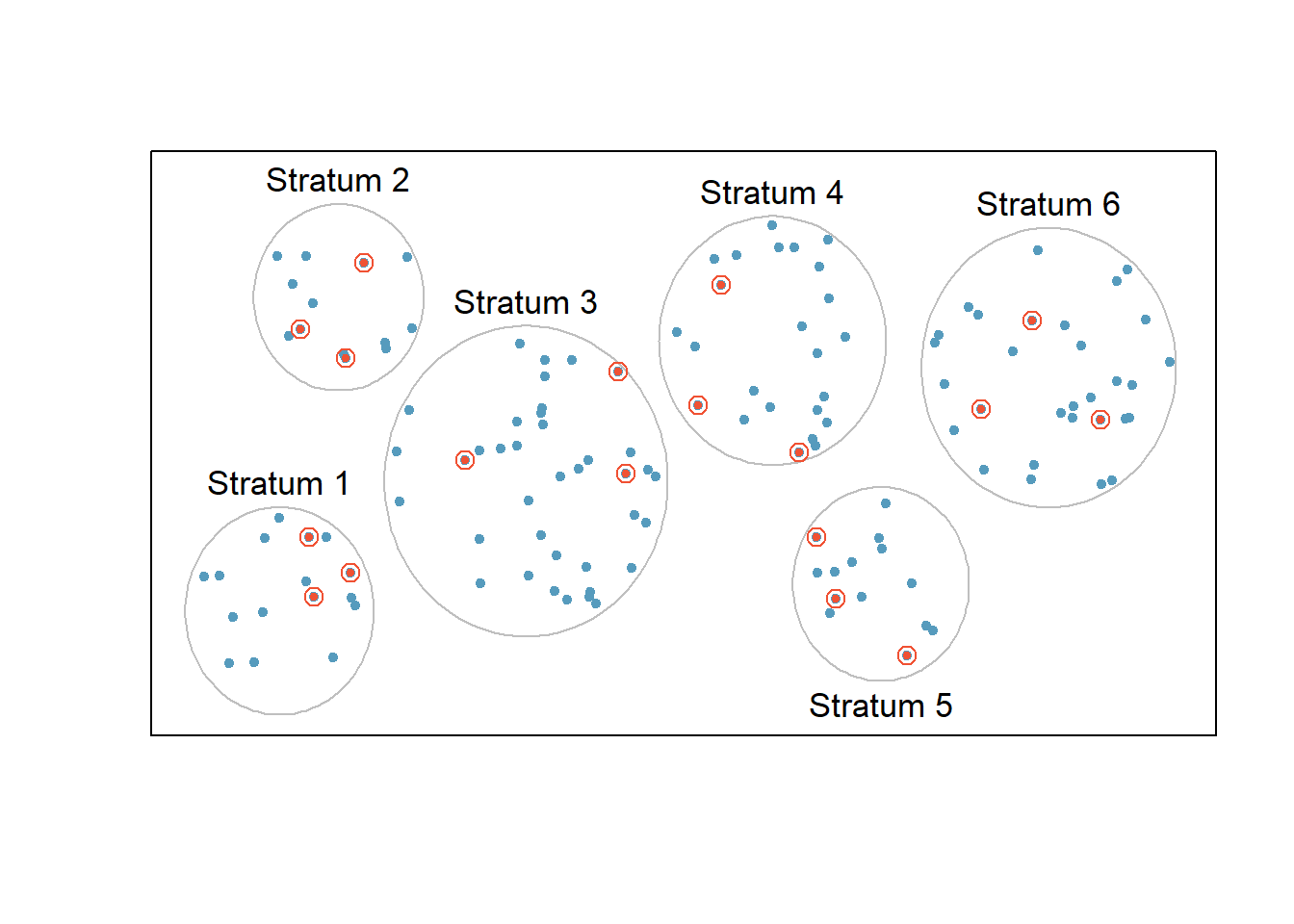
2.4.2 Stratified Sampling
- The population is divided into non-overlapping, homogeneous subgroups called strata .
- Then, SRS is employed to select a certain number or a certain proportion of the whole within each stratum.
Source: OpenIntro.Org
Example: Stratified Sampling (Optional)
Design a sample to survey \(500\) students using stratified sampling method.
\[ \text { Strata Sizes } \bbox[white,4px] { \color{black} { \begin{array}{c|c|c|c} \text{Gender} & \text{Undergraduate} & \text{Graduate} & \text{Total} \\ \hline \text{Female} & \text{3355} & \text{4693} & \text{8048} \\ \text{Male} & \text{3734} & \text{6687} & \text{10421} \\ \hline \text{Total} & \text{7089} & \text{11380} & \text{18469} \\ \end{array} } } \]
\[ \text { Strata Proportions } \bbox[yellow,4px] { \color{black} { \begin{array}{c|c|c|c} \text{Gender} & \text{Undergraduate} & \text{Graduate} & \text{Total} \\ \hline \text{Female} & \text{3355/18469 = .182} & \text{.254} & \text{.436} \\ \text{Male} & \text{.202} & \text{.362} & \text{.564} \\ \hline \text{Total} & \text{.384} & \text{.616} & \text{1.000} \\ \end{array} } } \]
\[ \text { Sample sizes } \bbox[lightblue,4px] { \color{black} { \begin{array}{c|c|c|c} \text{Gender} & \text{Undergraduate} & \text{Graduate} & \text{Total} \\ \hline \text{Female} & \text{.182(500)=91} & \text{127} & \text{218} \\ \text{Male} & \text{101} & \text{181} & \text{282} \\ \hline \text{Total} & \text{192} & \text{308} & \text{500} \\ \end{array} } } \]
Practice
Design a sample to survey \(1200\) students using stratified sampling method.
\[ \bbox[white,4px] { \color{black} { \begin{array}{c|c|c|c} \text{Gender} & \text{Undergraduate} & \text{Graduate} & \text{Professional} \\ \hline \text{Female} & \text{10588} & \text{4475} & \text{1421} \\ \text{Male} & \text{7762} & \text{3736} & \text{1153} \\ \hline \end{array} } } \]
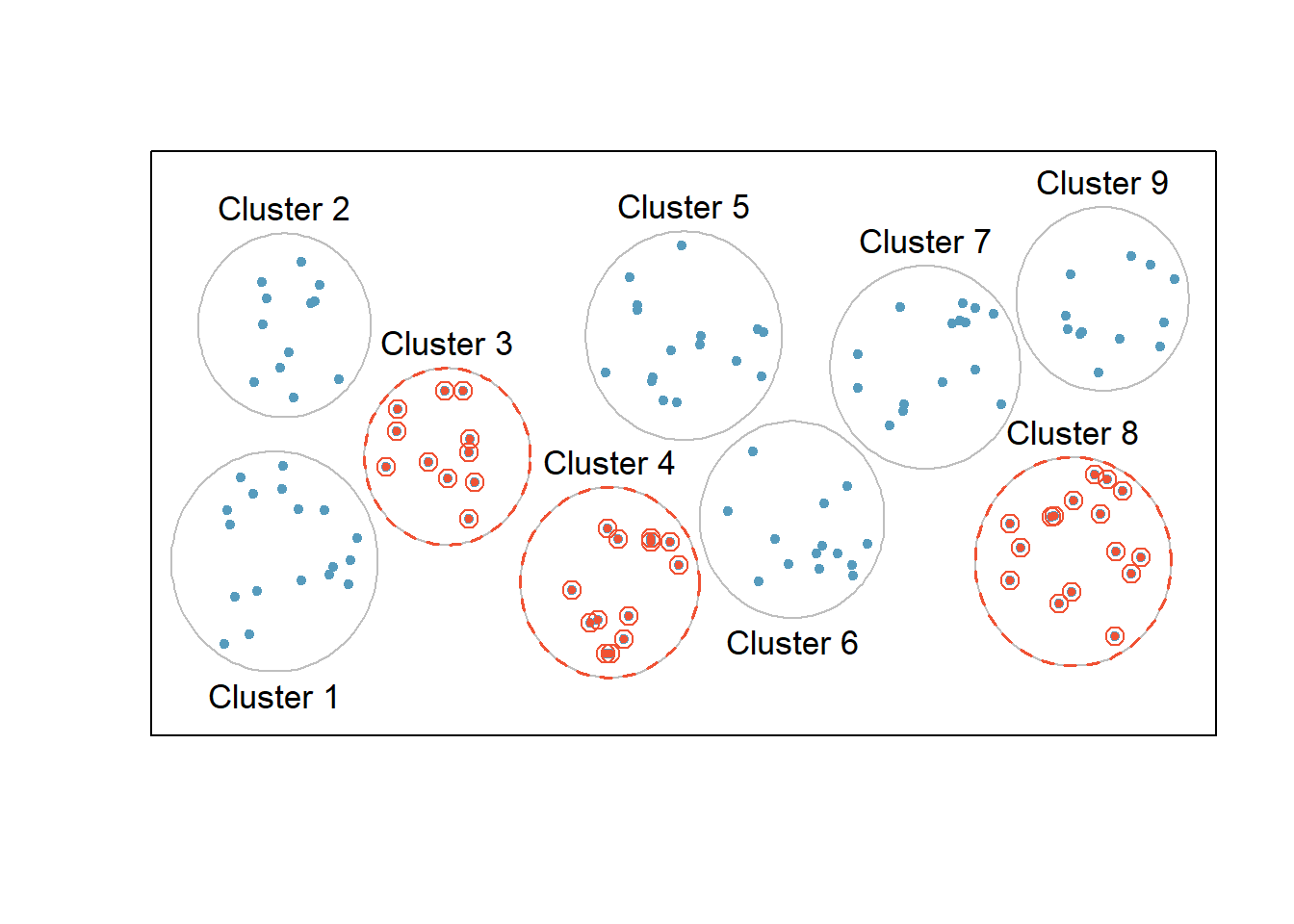
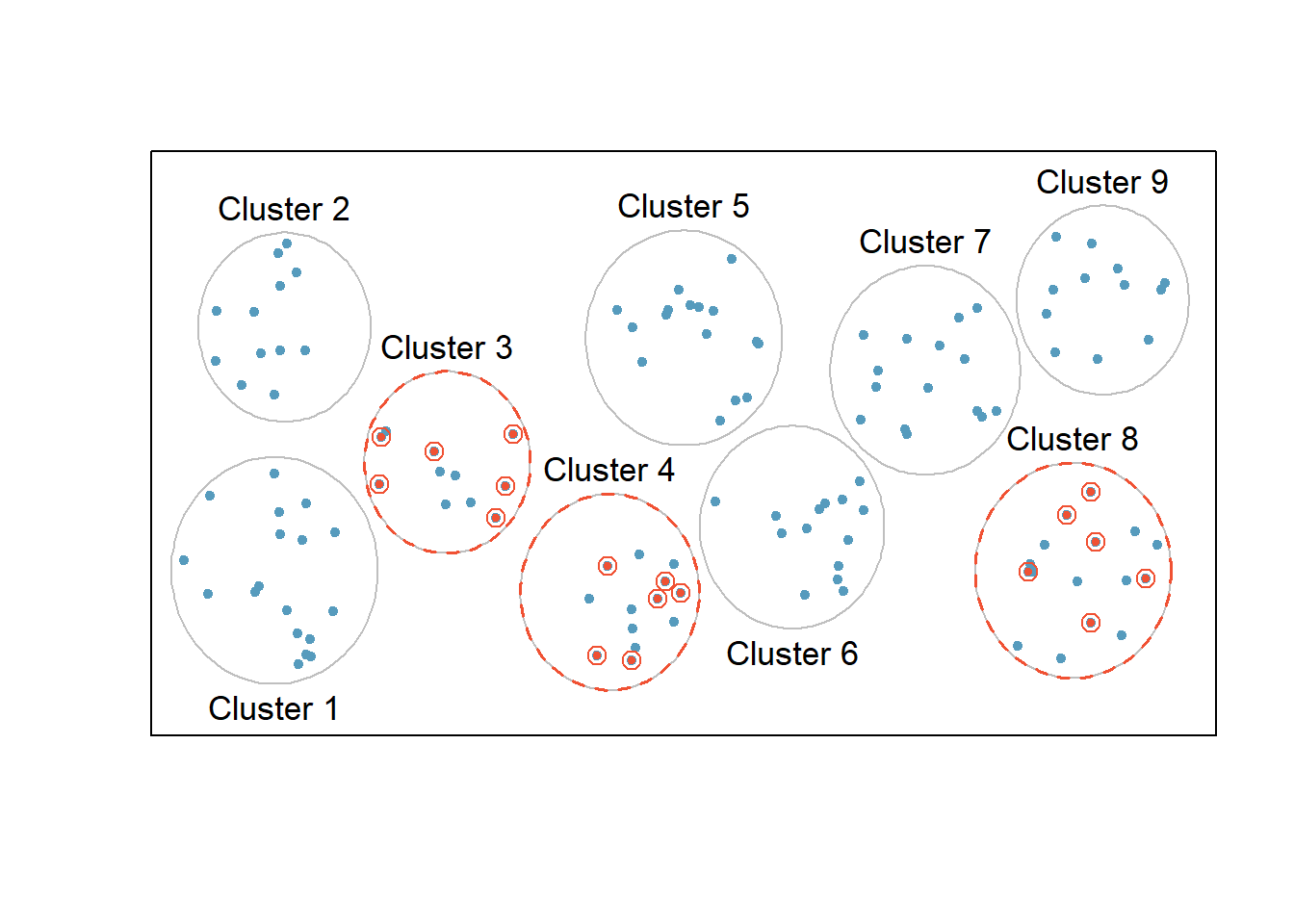
2.4.3 Cluster Sampling
- The population is often divided into non-overlapping mutually homogeneous yet internally heterogeneous subgroups called clusters. Cluster sampling is much like SRS, but instead of randomly selecting individuals, SRS is applied to select clusters.
- In other words, unlike stratified sampling, cluster sampling is most helpful when there is a lot of case-to-case variability within a cluster but the clusters themselves don’t look very different from one another. That is, we expect strata to be self-similar (homogeneous), while we expect clusters to be diverse (heterogeneous).
- The elements in each cluster are then sampled. If all elements in each sampled cluster are sampled, then this is referred to as a “one-stage” cluster sampling plan.
- Sometimes cluster sampling can be a more economical than random sampling technique than the alternatives. For example, if neighborhoods represented clusters, this sampling method works best when each neighborhood is very diverse. Because each neighborhood itself encompasses diversity, a cluster sample can reduce the time and cost associated with data collection, because the interviewer would need only go to some of the neighborhoods rather than to all parts of a city, in order to collect a useful sample.
One-Stage Cluster Sampling
Source: OpenIntro.Org
Multistage Cluster Sampling
A “multistage” or “multistage cluster” sampling is an extention of cluster sampling and involves two (or more) steps.
- First step is to take a cluster sample.
- Then, instead of including all of the individuals in these clusters in the sample, a second sampling method, usually SRS, is employed within each of the selected clusters.
In the neighborhood example, we could first randomly select some number of neighborhoods and then take a SRS from just those selected neighborhoods. As seen in Figure, stratified sampling requires observations to be sampled from every stratum. Multistage sampling selects observations only from those clusters that were randomly selected in the first step.
It is also possible to have more than two steps in multistage sampling. Each cluster may be naturally divided into subclusters. For example, each neighborhood could be divided into streets. To take a three-stage sample, we could first select some number of clusters (neighborhoods), and then, within the selected clusters, select some number of subclusters (streets). Finally, we could select some number of individuals from each of the selected streets.
Source: OpenIntro.Org
2.4.4 Nonrandom Sampling
Systematic Sampling
Select every \(k^{th}\) individual from a list of the population, where the position of the first person chosen is randomly selected from the \(k\) individuals. This will give a non-representative sample if there is a structure to the list.
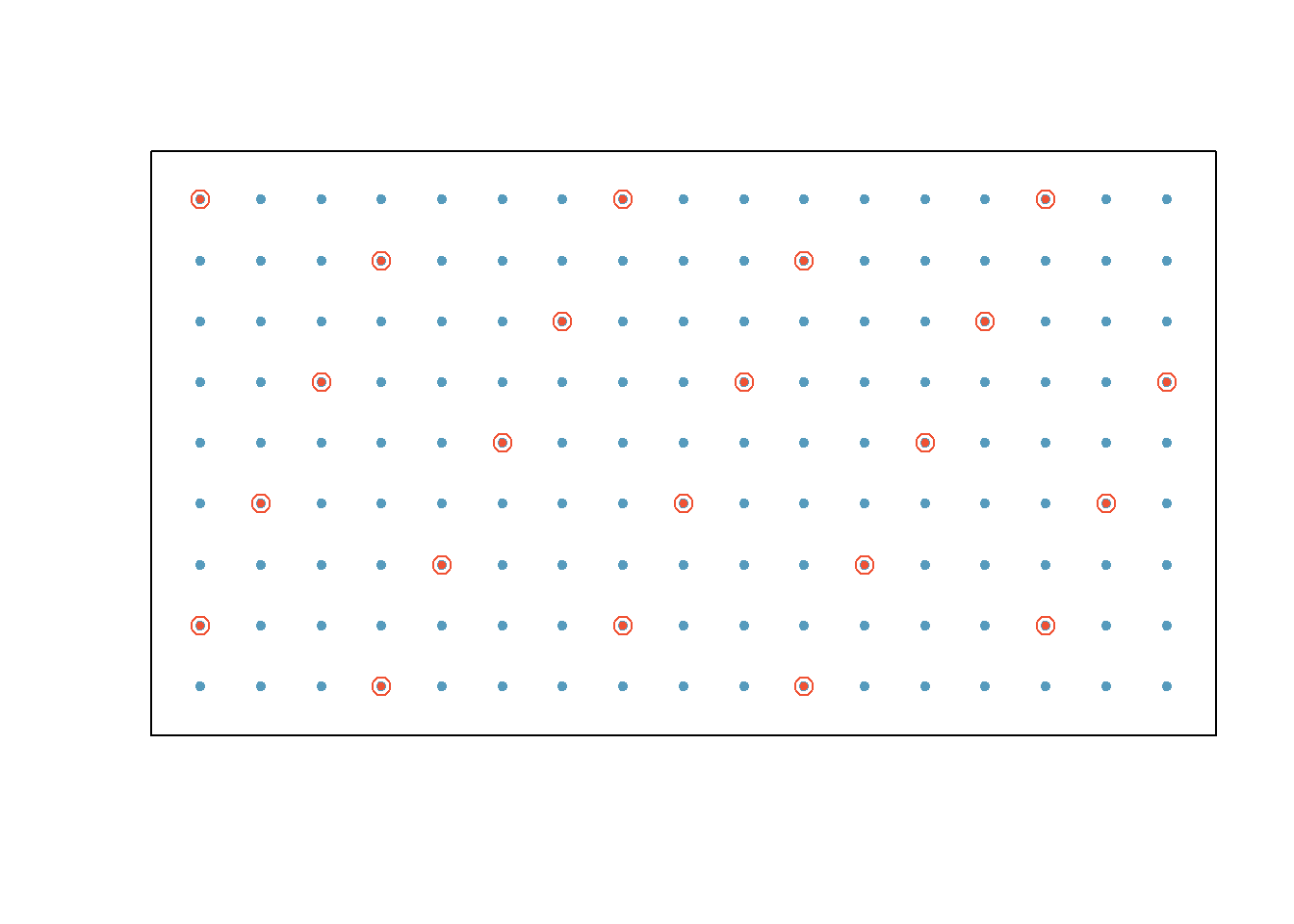
Source: OpenIntro.Org
Solve:
The human resource department at a certain company wants to conduct a survey regarding worker benefits. The department has an alphabetical list of all \(5465\) employees at the company and wants to conduct a systematic sample of size \(60\). What is \(k\)?
Convenience or Volunteer Sampling
Use the first \(n\) individuals that are available or the individuals who volunteer to participate. This is almost sure to give a non-representative sample which cannot be generalized to the population.
Voluntary response samples are often used by the media to try to engage the audience. For example, a radio announcer will invite people to call the station to say what they think. Voluntary response samples are never reliable for the following reasons: * People who volunteer an opinion tend to have stronger opinions than is typical of the population. * People with negative opinions are often more likely to volunteer their response.
Exercise: Identifying Sampling Methods
A researcher randomly selects 20 Taco Bell locations and surveys all the employees at those locations.
A news station hosts a call-in survey about whether physician-assisted death should be legalized in all states.
A researcher randomly selects an LED TV out of the first 200 LED TVs on an assembly line and also selects every 200th LED TV after that.
In a study at a community college, 30 instructors are randomly selected from full time instructors and 50 instructors are randomly selected from part-time instructors.
The City Hall of Spring Hill, Kansas, creates a frame of its 5730 residents and randomly selects 60 residents.
Every 10 years, the U.S. Census Bureau attempts to count every person living in the United States. To check the accuracy of their count in a certain city, they draw a sample of census districts and recount everyone in the sampled districts. What kind of sample is formed by the people who are recounted?
Example: Non-Representative Sample

Survey
- Surveyed 10 million people who were subscribers or had telephones.
- 2.4 million people responded (i.e. 24% response rate)
Prediction
Landslide victory of Landon.
Election Result
Landslide victory of Roosevelt.
What did go wrong with the poll?
Sample was drawn from telephone directories, club membership, magazine subscibers, etc. who were upper middle class people, largely excluding poor unemployed people.
The sample suffered from both selection and nonresponse bias.
2.5 Bias and Precision
Bias
Bias is the degree to which a procedure systematically overestimates or underestimates a population value.
A study conducted by a procedure that tends to overestimate or underestimate a population value is said to be biased.
A study conducted by a procedure that produces the correct result on the average is said to be unbiased.
Precision
The standard deviation of the estimator.
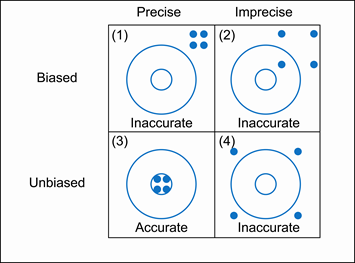
\[ \begin{aligned} \text{Mean Squared Error, MSE} &= precision^2 + bias^2 \\ \text{Root Mean Squared Error, RMSE} &= \sqrt{MSE} \end{aligned} \]
2.6 Sampling Errors
Statistical Inference
Inferential Statistics is the practice of using information from a sample to draw conclusions about the entire population.
It is the process of making judgments about the parameters of a population and the reliability of statistical relationships, typically on the basis of random sampling.
\(\require{AMScd}\) \[ \begin{CD} Sample @> {\text {statistical inference}} >> Population \end{CD} \]
\[\underbrace{\text {sample statistic}}_{\text{investigator knows}} = \underbrace{\text {population parameter}}_{\text{investigator wants to know}} + \underbrace{\text {bias}}_{\text{nonsampling error}} + \underbrace{\text {chance variation}}_{\text{random sampling error}} \]
Random Sampling Error - occurs when the sample has been selected with a random method, but there is a discrepancy between a sample result and the true population result.
Non-sampling Error - is the results of human error, including such factors as wrong data entries, computing errors, questions with biased wording, false data provided by respondents, forming biased conclusions, or applying statistical methods that are not appropriate for the circumstances.
A sampling method that consistently underestimates or overestimates some characteristics of the population is said to be biased.
Selection/Sampling bias - occurs when the sample is selected in such a way that it systematically excludes or underrepresented part of the population. Voluntary response, self-interest, and social accountability bias fall into this category.
- An online survey conducted to estimate the percentage of Americans who have a Facebook account.
- The survey is biased because people who go online are favored.
- People who never go online cannot participate in the poll.
Nonresponse bias - occurs when responses are not obtained from all individuals selected for inclusion in a sample. It happens if individuals refuse to be part of the study or if the research cannot track down individuals identified to be in the sample.
Measurement or response bias - occurs when the data are collected in such a way that it tends to result in observed values that are different from the actual value in some systematic way. Contributing factors: question wording and order; mode of survey; influence of the interviewer; people might exaggerate how much money they earn; or a researcher might record the information incorrectly etc.
Leading question bias is a type of measurement bias. For example, compare the impact on the respondent of the following three questions:
- Do you brag about your past successes with others?
- Do you inspire others by sharing your past successes?
- Do you share your past successes with others?
Nonrandom Sampling Error - is the results of using a sampling method that is not random, such as using a convenience sample or a voluntary response sample.
Statistical Studies
Explanatory and Response Variables
In statistical studies, we want to know whether a variable \(x\) explains (or affects) another variables \(y\). The \(x\) variable is called the explanatory or independent variable. The \(y\) variable is called the response or dependent variable.
Association vs. Causation
There is an association between an explanatory and response variable when the response variable changes as the explanatory variable changes.
If the change in the explanatory variable causes the change in the response variable, then there is a causation between the variables.
2.7 Observational Studies
Generally, data in observational studies are collected on specific characteristics only by passively monitoring study participants, but the observers don’t attempt to modify the individuals being studied, or, in other words, don’t attempt to influence the value of either the response or explanatory variables. That is, in an observational study, the researcher simply observes the behavior of the individuals in the study and records the values of the explanatory and response variables. These studies are inexpensive and good for discovering relationships related to rare outcomes. They are generally only sufficient to show associations.
Key points:
- Observational studies seldom support causal inference, \(X \rightarrow Y\).
- Variables in observational studies are often measured concurrently. Such measurements provide no temporal precedence. The study design cannot determine which of the two variables, a presumed cause and a presumed effect, occurred first.
- Hence, in this kind of design, the sole basis for causal inference is assumption, or ruling out alternative explanations of the association between \(X\) and \(Y\), as well as measuring other presumed causes of \(Y\).
- It is possible to correctly infer causation in nonexperimental designs, but the hurdles are much greater. As an example, think about the causal link cigarette smoking and lung cancer.
Types of observational studies:

In a cohort study, a group of subjects is studied to determine whether various factors of interest are associated with an outcome.
A prospective (or longitudinal) study is the one where the subjects are studied over time.
Example: One of the most famous prospective cohort studies was the Framingham Heart Study. This study began in 1948 with \(5209\) men and women from the town of Framingham, Massachusetts. Every two years, these subjects were given physical exams and lifestyle interviews, which were studied to discover factors that increase the risk of heart disease.
A cross-sectional study is where the subjects are measured at one point in time, not over a period of time.
Example: I. Lang and colleagues studied the health effects of Bisphenol A, a chemical found in the linings of food and beverage containers. They measured the levels of Bisphenol A in urine samples from \(1455\) adults and found that people with higher levels of Bisphenol A were more likely to have heart disease and diabetes.
In a retrospective study, data from the subjects is collected after the outcome has occurred (through examinations of records, interviews, and so on).
Example: In a study published in The New England Journal of Medicine, T. Adams and colleagues sampled 9949 people who had undergone gastric bypass surgery between 5 and 15 years previously, along with \(9668\) obese patients who had not had bypass surgery. They looked back in time to see which patients were still alive. They found that the survival rates for the surgery patients were greater than for those who had not undergone surgery.
In a ccase-control study , two samples are drawn where one consists of people who have the disease of interest (the cases), and the other consists of people who do not (the controls). The investigators look back in time to determine whether a factor of interest differs between the groups.
Example: S.S. Nielsen and colleagues conducted a case-control study to determine whether exposure to pesticides is related to brain cancer in children. They sampled 201 children who had been diagnosed with brain cancer, and 285 children who did not. They interviewed the parents to estimate the extent to which the children had been exposed to pesticides. They did not find a clear relationship between pesticide exposure and brain cancer.
Observational Study: drinking coffee and longevity
Coffee drinkers may live longer - nytimes.com, May 16, 2012.
Coffee may help you live longer, study suggests - thestar.com, May 17, 2012.
No, drinking coffee probably won’t make you live longer - washingtonpost.com, May 17, 2012.
Association of coffee drinking with total and cause-specific mortality,” New England Journal of Medicine, May 2012.
Sample Size: 400,000
Age Range: 50-71 years
Period: 1995 - 2008
Death: 52,000
How would you interpret the result?
Confounding Variable
A confounding variable is an explanatory variable that is associated with both the explanatory (or treatment) and response variables (or outcomes). Simultaneously with the explanatory variable, it may cause the response variable to change during the study. Because of the confounding variable’s association with both variables, we do not know if the response is due to the explanatory variable or due to the confounding variable.

Sun exposure is a confounding factor because it is associated with both the use of sunscreen and the development of skin cancer. People who are out in the sun all day are more likely to use sunscreen (treatment), and people who are out in the sun (confounder) all day are more likely to get skin cancer (outcome).
Lurking Variable
Lurking variables are variables that are not considered in the analysis, but may affect the nature of the relationship between the explanatory variable and the outcome. Lurking variables are related to both the explanatory and response variables, and this relation is what creates the apparent association between the explanatory variable and response variable in the study. For example, lifestyle (healthy or not) is associated with the likelihood of getting an influenza shot as well as the likelihood of contracting pneumonia or influenza.
Table: 20-year survival status of women by smoking status
\[ \begin{array}{c|lcr} & \text{Smoker} \\ & \text{Yes} & \text{No} \\ \hline \text {Dead} & 0.239 & 0.314 \\ \text {Alive} & 0.761 & 0.686 \end{array} \]
Are smokers less likely to die?
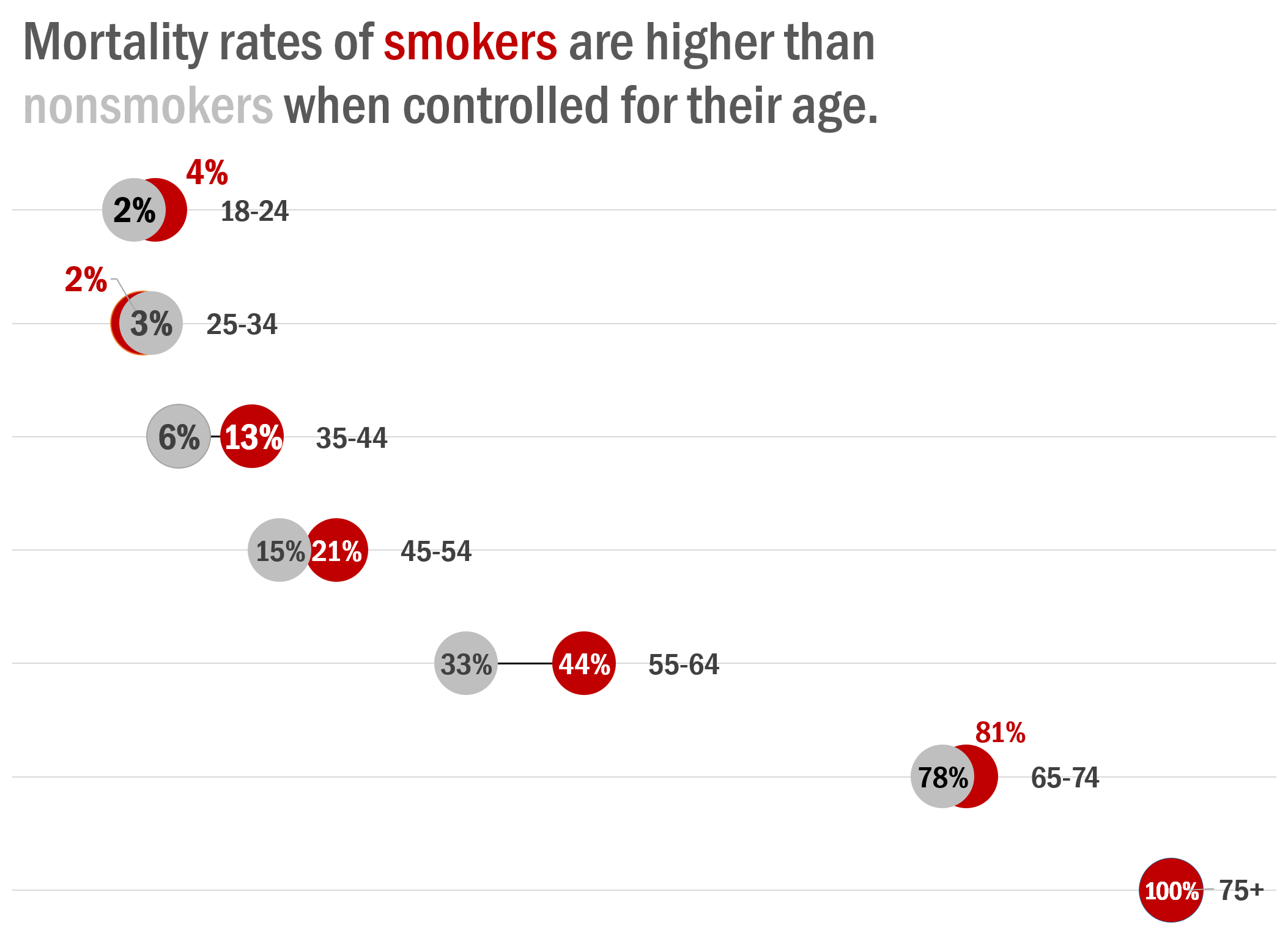
The big difference between lurking variables and confounding variables is that lurking variables are not considered in the study (for example, we did not consider lifestyle in the pneumonia study), whereas confounding variables are measured in the study (for example, we measured morning versus afternoon classes).
The bottom line is that both lurking variables and confounding variables can confound the results of a study, so a researcher should be mindful of their potential existence.
2.8 Experimental Design
While observational studies are effective tools for answering certain research questions, experiments are essential to measure the effect of a treatment. In an experiment, we apply some treatment and then proceed to observe its effects on the individuals.
Subject or Experimental Unit: Entity who is participating in the study.
Treatment Group: The group of subjects that receives treatments.
Control Group: The group of subjects that receives no treatment.
Outcome or Response Variable: The outcome of interest, measured on each subject.
Factor: The categorical variable that explains the outcome of the experiment. Each category is called level.
Randomization: the investigator assigns treatments to the experimental units at random.
Example: To assess the effectiveness of a new method for teaching arithmetic to elementary school children, a simple random sample of \(30\) first graders were taught with the new method, and another simple random sample of \(30\) first graders were taught with the currently used method. At the end of eight weeks, the children were given a test to assess their knowledge.
Blinding: When researchers keep the subjects uninformed about their treatment, the study is said to be blind. Its purpose is to reduce the potential for both researchers’ and subjects’ emotional bias.
- Subjects would not know which experimental group they are assigned to.
- The researcher (i.e. the person who is measuring the outcome) would not know which treatment is assigned to which experimental unit.
Single-blind: only one type of blinding is applied.
Double-blind: both types of blinding are applied.
Placebo: A substance or treatment with no active ingredients. The control group receives the placebo treatment.
This phenomenon, in which the recipient perceives an improvement in condition due to personal expectations, rather than the treatment itself, is known as the placebo effect.
Principles of Experimental Design
Well-conducted experiments are built on three main principles.
Direct Control
Researchers assign treatments to cases, and they do their best to control any other differences in the groups. They want the groups to be as identical as possible except for the treatment, so that at the end of the experiment any difference in response between the groups can be attributed to the treatment and not to some other confounding or lurking variable. Direct control refers to variables that the researcher can control.
Randomization
Researchers randomize patients into treatment groups to account for variables that cannot be controlled. Randomizing patients into the treatment or control group helps even out the effects of such differences, and it also prevents accidental bias from entering the study.
- In a randomized experiment, small differences among treatment groups are likely to be due only to chance.
- If there are large differences in outcomes among the treatment groups, we can conclude that the differences are due to the treatments.
Replication
In a single study, replication is done by imposing the treatment on a sufficiently large number of subjects or experimental units. Scientists may also replicate the entire experiment on an entirely different population of experimental units to verify earlier findings.
2.8.1 Randomized Blocked Design
Researchers sometimes know or suspect that another variable, other than the treatment, influences the response. Under these circumstances, they may carry out a blocked experiment. In this design, they first group individuals into blocks based on the identified variable (in other words, form blocks or groups of subjects with similar characteristics) and then randomize subjects within each block to the treatment groups. This strategy is referred to as blocking. For example, blocks can be designed based on gender or age group of subjects.
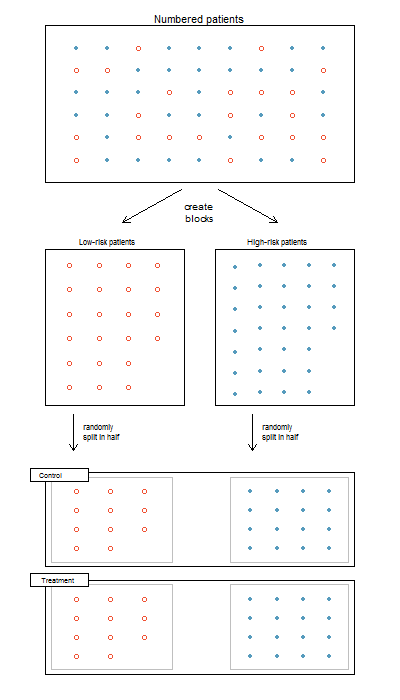
2.8.2 Completely Randomized Experimental Design
A completely randomized experimental design is one in which the subjects or experimental units are randomly assigned to each group in the experiment.
Source: OpenIntro.Org
Case Study 1: PATRICIA Study | PApilloma TRIal against Cancer In young Adults
The Lancet, Volume 374, Issue 9686, Pages 301 - 314, 25 July 2009
Efficacy of human papillomavirus (HPV) - 16/18 AS04-adjuvanted vaccine against cervical infection and precancer caused by oncogenic HPV types (PATRICIA); final analysis of a double-blind, randomized study in young women.
Paavonen, et. al.
\[ \begin{array}{c|c} {\text{Response Variable} \\ \text {(Acquired an infection)}} & {\text{Explanatory Variable} \\ \text{(Given the HPV vaccine)}} \\ \hline \text{Yes} & \text{Yes} \\ \text{No} & \text{No} \\ \end{array} \]
\[ \bbox[yellow,5px] { \color{black} { \begin{array}{c} {\text{Factor 1} \\ \text{(2 Levels)}} \\ \hline \text{Drug A} \\ \text{Drug B} \end{array} } } \]
\[ \bbox[silver,5px] { \color{black} { \begin{array}{c} {\text{Factor 2} \\ \text{(2 Levels)}} \\ \hline \text{Dose A} \\ \text{Dose B} \end{array} } } \]
\[ \bbox[5px,border:2px solid red] { \begin{array}{c} \text{4 Treatments} \\ \hline \text{Drug A & Dose A}\\ \text{Drug A & Dose B}\\ \text{Drug B & Dose A}\\ \text{Drug B & Dose B} \end{array} } \]
Case Study 2: Ischemic Preconditioning | Effect on Muscular Endurance
Can Ischemic Preconditioning improve athletic performance?
- Experimental units: 40 male teenagers
- Response Variable: length of time a wall squat position can be held
- Control Groups: 2 groups who received 0 lb pressure
- Control of Extraneous Factors: Age, sex, athletic ability
- Randomization: Randomly assigned 10 experimental units to each of 4 treatment groups
\[ \bbox[yellow,5px] { \color{black} { \begin{array}{c|c} \text{Factor1} & {\text{Amount of pressure} \\ \text{applied by the} \\ \text{bloodpressure cuff}} \\ \hline \text{Level 1} & \text{20 lb} \\ \text{Level 2} & \text{0 lb} \\ \end{array} } } \]
\[ \bbox[silver,5px] { \color{black} { \begin{array}{c|c} \text{Factor2} & {\text{Length of time pressure} \\ \text{was applied}} \\ \hline \text{Level 1} & \text{10 min} \\ \text{Level 2} & \text{20 min} \\ \end{array} } } \]
\[ \bbox[5px,border:2px solid red] { \begin{array}{c} \text{4 Treatments} \\ \hline \text{20 lb/10 min}\\ \text{20 lb/20 min}\\ \text{0 lb/ 10 min}\\ \text{0 lb/ 20 min} \end{array} } \]
2.8.3 Matched-Pairs Design
A Matched-Pairs design is an experimental design in which the experimental units are paired up. The pairs are selected so that they are related in some way (that is, the same person before and after a treatment, twins, spouses, same geographical location, and so on). There are only two levels of treatment in a Matched-Pairs design.
In Matched-Pairs design, one matched individual will receive one treatment and the other receives a different treatment. The matched pair is randomly assigned to the treatment using a coin flip or a random-number generator. We then look at the difference in the results of each matched pair. One common type of Matched-Pairs design is to measure a response variable on an experimental unit before and after a treatment is applied. In this case, the individual is matched against themself. These experiments are sometimes called before-after or pretest-posttest experiments.
Components of a Well-Designed Study
- There should be a control group and at least one treatment group.
- Individuals should be randomly assigned to the control and treatment group(s).
- The sample size should be large enough.
- A placebo should be used when appropriate.
- The study should be double-blind when possible. If this is impossible, then the study should be single-blind if possible.
Practice: Identifying an Experiment and an Observational Study
Identify whether the study is an experiment or an observational study. Discuss whether the components of a good study were used.
For five years, the author taught an innovative intermediate algebra course in which students learned by working in groups. Then the author compared the proportion of his successful intermediate algebra students who passed trigonometry with the proportion of other professors’ successful intermediate algebra students who passed trigonometry.
Practice: Redesign an Observational Study into a Well-Designed Experiment
A researcher wants to determine whether taking vitamin C helps people avoid getting the flu and the common cold. She randomly selects 100 people and asks them whether they take vitamin C and how often they had the flu or a cold in the past year. The researcher analyzes the responses and concludes that vitamin C helps people avoid the flu and colds.
Describe some problems with the observational study. Include in your description at least one possible lurking or confounding variable and identify which type it is.
Redesign the study so that it is a well-designed experiment.